Deck 9: Data Mining
Full screen (f)
Question
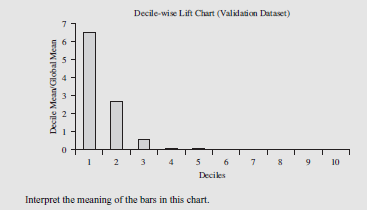
A data mining routine has been applied to a transaction dataset and has classified 88 records as fraudulent (30 correctly so) and 952 as nonfraudulent (920 correctly so). The decile-wise lift chart for a transaction data model:
Question
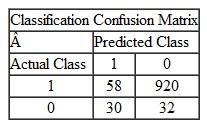
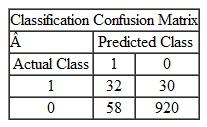
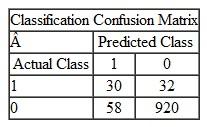
Which of the following situations represents the confusion matrix for the transactions data mentioned in question 1 above? Explain your reasoning.
A
 B
B
 C
C
 D
D
A
B C D Question
Calculate the classification error rate for the following confusion matrix. Comment on the pattern of misclassifications. How much better did this data mining technique do as compared to a naive model?
Question
Question
Question
For a data mining classification technique the validation data set lift charts are shown below. What confidence in the model would you express given this evidence?
Question
Question

Unlock Deck
Sign up to unlock the cards in this deck!
Unlock Deck
Unlock Deck
1/8
Play
Full screen (f)
Deck 9: Data Mining
1
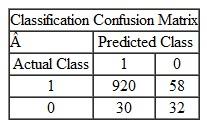
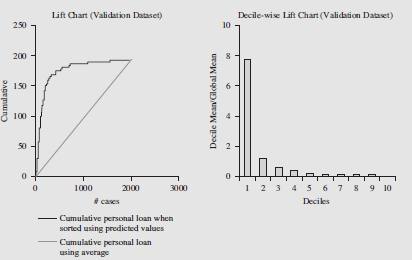
A data mining routine has been applied to a transaction dataset and has classified 88 records as fraudulent (30 correctly so) and 952 as nonfraudulent (920 correctly so). The decile-wise lift chart for a transaction data model:
By selecting the first decile of the scored results the researcher will have chosen approximately 6.5 times the number of correct classifications than if a random selection process had been used. In other words, the model is doing much better than a random selection process in forecasting whether a particular transaction is fraudulent or nonfraudulent.
2
Which of the following situations represents the confusion matrix for the transactions data mentioned in question 1 above? Explain your reasoning.
A
B
C
D
A
B C D Assuming that "1" is fraudulent and "0" is nonfraudulent, "C" is the correct matrix.
3
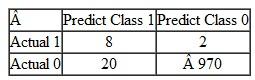
Calculate the classification error rate for the following confusion matrix. Comment on the pattern of misclassifications. How much better did this data mining technique do as compared to a naive model?
The model misclassifies class "1" at a rate of 2 out of 10 cases; it misclassifies "0" at a rate of 20 out of 990.
The naïve model would choose randomly choose 10 of the 1,000 observations as class "1" and the remaining 990 observations would be classified as "0."
The naïve model would choose randomly choose 10 of the 1,000 observations as class "1" and the remaining 990 observations would be classified as "0."
4
Explain what is meant by Bayes' theorem as used in the Naive Bayes model.
Unlock Deck
Unlock for access to all 8 flashcards in this deck.
Unlock Deck
k this deck
5
Explain the difference between a training data set and a validation data set. Why are these data sets used routinely with data mining techniques in the XLMiner© program and not used in the ForecastX™ program? Is there, in fact, a similar technique presented in a previous chapter that is much the same as partitioning a data set?
Unlock Deck
Unlock for access to all 8 flashcards in this deck.
Unlock Deck
k this deck
6
For a data mining classification technique the validation data set lift charts are shown below. What confidence in the model would you express given this evidence?
Unlock Deck
Unlock for access to all 8 flashcards in this deck.
Unlock Deck
k this deck
7
In data mining the candidate model should be applied to a data set that was not used in the estimation process in order to find out the accuracy on unseen data; that unseen data set. What is the unseen data set called? How is the unseen data set selected?
Unlock Deck
Unlock for access to all 8 flashcards in this deck.
Unlock Deck
k this deck
8
Explain what the "k" in the k-Nearest-Neighbor model references.
Unlock Deck
Unlock for access to all 8 flashcards in this deck.
Unlock Deck
k this deck
Unlock Deck
Unlock for access to all 8 flashcards in this deck.


