Deck 18: Professional Data Engineer on Google Cloud Platform
Full screen (f)
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
You are deploying a new storage system for your mobile application, which is a media streaming service. You decide the best fit is Google Cloud Datastore. You have entities with multiple properties, some of which can take on multiple values. For example, in the entity 'Movie' the property 'actors' and the property 'tags' have multiple values but the property 'date released' does not. A typical query would ask for all movies with actor= ordered by date _ released or all movies with tag=Comedy date_released. How should you avoid a combinatorial explosion in the number of indexes?
A) Manually configure the index in your index config as follows:
B)
C) Set the following in your entity options: exclude_from_indexes = 'actors, tags' Set the following in your entity options: exclude_from_indexes = 'actors, tags'
D) Set the following in your entity options: exclude_from_indexes = 'date_published' exclude_from_indexes = 'date_published'
A) Manually configure the index in your index config as follows:
B)
C) Set the following in your entity options: exclude_from_indexes = 'actors, tags' Set the following in your entity options: exclude_from_indexes = 'actors, tags'
D) Set the following in your entity options: exclude_from_indexes = 'date_published' exclude_from_indexes = 'date_published'
Question
You have some data, which is shown in the graphic below. The two dimensions are X and Y, and the shade of each dot represents what class it is. You want to classify this data accurately using a linear algorithm. To do this you need to add a synthetic feature. What should the value of that feature be? 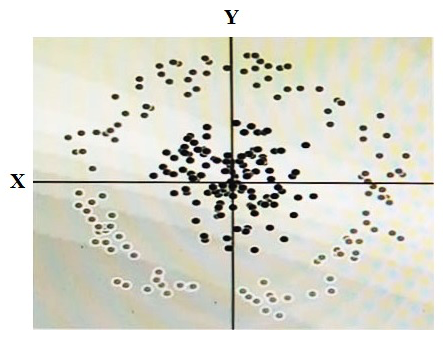
A) X^2+Y^2
B) X^2
C) Y^2
D) cos(X)
A) X^2+Y^2
B) X^2
C) Y^2
D) cos(X)
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
You are using Google BigQuery as your data warehouse. Your users report that the following simple query is running very slowly, no matter when they run the query: SELECT country, state, city FROM [myproject:mydataset.mytable] GROUP BY country You check the query plan for the query and see the following output in the Read section of Stage:1: ![<strong>You are using Google BigQuery as your data warehouse. Your users report that the following simple query is running very slowly, no matter when they run the query: SELECT country, state, city FROM [myproject:mydataset.mytable] GROUP BY country You check the query plan for the query and see the following output in the Read section of Stage:1: What is the most likely cause of the delay for this query?</strong> A) Users are running too many concurrent queries in the system B) The [myproject:mydataset.mytable] table has too many partitions The [myproject:mydataset.mytable] table has too many partitions C) Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values D) Most rows in the [myproject:mydataset.mytable] table have the same value in the country column, causing data skew Most rows in the table have the same value in the country column, causing data skew <div style=padding-top: 35px>](https://storage.examlex.com/C1428/11ec58c7_4d7a_27e3_a4e0_597e04f82d22_C1428_00.jpg) What is the most likely cause of the delay for this query?
What is the most likely cause of the delay for this query?
A) Users are running too many concurrent queries in the system
B) The [myproject:mydataset.mytable] table has too many partitions The [myproject:mydataset.mytable] table has too many partitions
C) Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values
D) Most rows in the [myproject:mydataset.mytable] table have the same value in the country column, causing data skew Most rows in the table have the same value in the country column, causing data skew
What is the most likely cause of the delay for this query?A) Users are running too many concurrent queries in the system
B) The [myproject:mydataset.mytable] table has too many partitions The [myproject:mydataset.mytable] table has too many partitions
C) Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values
D) Most rows in the [myproject:mydataset.mytable] table have the same value in the country column, causing data skew Most rows in the table have the same value in the country column, causing data skew
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question
Question

Unlock Deck
Sign up to unlock the cards in this deck!
Unlock Deck
Unlock Deck
1/256
Play
Full screen (f)
Deck 18: Professional Data Engineer on Google Cloud Platform
1
MJTelco Case Study Company Overview MJTelco is a startup that plans to build networks in rapidly growing, underserved markets around the world. The company has patents for innovative optical communications hardware. Based on these patents, they can create many reliable, high-speed backbone links with inexpensive hardware. Company Background Founded by experienced telecom executives, MJTelco uses technologies originally developed to overcome communications challenges in space. Fundamental to their operation, they need to create a distributed data infrastructure that drives real-time analysis and incorporates machine learning to continuously optimize their topologies. Because their hardware is inexpensive, they plan to overdeploy the network allowing them to account for the impact of dynamic regional politics on location availability and cost. Their management and operations teams are situated all around the globe creating many-to-many relationship between data consumers and provides in their system. After careful consideration, they decided public cloud is the perfect environment to support their needs. Solution Concept MJTelco is running a successful proof-of-concept (PoC) project in its labs. They have two primary needs: Scale and harden their PoC to support significantly more data flows generated when they ramp to more than 50,000 installations. Refine their machine-learning cycles to verify and improve the dynamic models they use to control topology definition. MJTelco will also use three separate operating environments - development/test, staging, and production - to meet the needs of running experiments, deploying new features, and serving production customers. Business Requirements Scale up their production environment with minimal cost, instantiating resources when and where needed in an unpredictable, distributed telecom user community. Ensure security of their proprietary data to protect their leading-edge machine learning and analysis. Provide reliable and timely access to data for analysis from distributed research workers Maintain isolated environments that support rapid iteration of their machine-learning models without affecting their customers. Technical Requirements Ensure secure and efficient transport and storage of telemetry data Rapidly scale instances to support between 10,000 and 100,000 data providers with multiple flows each. Allow analysis and presentation against data tables tracking up to 2 years of data storing approximately 100m records/day Support rapid iteration of monitoring infrastructure focused on awareness of data pipeline problems both in telemetry flows and in production learning cycles. CEO Statement Our business model relies on our patents, analytics and dynamic machine learning. Our inexpensive hardware is organized to be highly reliable, which gives us cost advantages. We need to quickly stabilize our large distributed data pipelines to meet our reliability and capacity commitments. CTO Statement Our public cloud services must operate as advertised. We need resources that scale and keep our data secure. We also need environments in which our data scientists can carefully study and quickly adapt our models. Because we rely on automation to process our data, we also need our development and test environments to work as we iterate. CFO Statement The project is too large for us to maintain the hardware and software required for the data and analysis. Also, we cannot afford to staff an operations team to monitor so many data feeds, so we will rely on automation and infrastructure. Google Cloud's machine learning will allow our quantitative researchers to work on our high-value problems instead of problems with our data pipelines. MJTelco's Google Cloud Dataflow pipeline is now ready to start receiving data from the 50,000 installations. You want to allow Cloud Dataflow to scale its compute power up as required. Which Cloud Dataflow pipeline configuration setting should you update?
A) The zone
B) The number of workers
C) The disk size per worker
D) The maximum number of workers
A) The zone
B) The number of workers
C) The disk size per worker
D) The maximum number of workers
The zone
2
Your company is streaming real-time sensor data from their factory floor into Bigtable and they have noticed extremely poor performance. How should the row key be redesigned to improve Bigtable performance on queries that populate real-time dashboards?
A) Use a row key of the form. Use a row key of the form .
B) Use a row key of the form. .
C) Use a row key of the form#. #.
D) Use a row key of the form >##. >##.
A) Use a row key of the form
B) Use a row key of the form
C) Use a row key of the form
D) Use a row key of the form >#
Use a row key of the form . Use a row key of the form .
3
You are designing a basket abandonment system for an ecommerce company. The system will send a message to a user based on these rules: No interaction by the user on the site for 1 hour Has added more than $30 worth of products to the basket Has not completed a transaction You use Google Cloud Dataflow to process the data and decide if a message should be sent. How should you design the pipeline?
A) Use a fixed-time window with a duration of 60 minutes.
B) Use a sliding time window with a duration of 60 minutes.
C) Use a session window with a gap time duration of 60 minutes.
D) Use a global window with a time based trigger with a delay of 60 minutes.
A) Use a fixed-time window with a duration of 60 minutes.
B) Use a sliding time window with a duration of 60 minutes.
C) Use a session window with a gap time duration of 60 minutes.
D) Use a global window with a time based trigger with a delay of 60 minutes.
Use a global window with a time based trigger with a delay of 60 minutes.
4
Your company uses a proprietary system to send inventory data every 6 hours to a data ingestion service in the cloud. Transmitted data includes a payload of several fields and the timestamp of the transmission. If there are any concerns about a transmission, the system re-transmits the data. How should you deduplicate the data most efficiency?
A) Assign global unique identifiers (GUID) to each data entry.
B) Compute the hash value of each data entry, and compare it with all historical data.
C) Store each data entry as the primary key in a separate database and apply an index.
D) Maintain a database table to store the hash value and other metadata for each data entry.
A) Assign global unique identifiers (GUID) to each data entry.
B) Compute the hash value of each data entry, and compare it with all historical data.
C) Store each data entry as the primary key in a separate database and apply an index.
D) Maintain a database table to store the hash value and other metadata for each data entry.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
5
Your company's customer and order databases are often under heavy load. This makes performing analytics against them difficult without harming operations. The databases are in a MySQL cluster, with nightly backups taken using mysqldump. You want to perform analytics with minimal impact on operations. What should you do?
A) Add a node to the MySQL cluster and build an OLAP cube there.
B) Use an ETL tool to load the data from MySQL into Google BigQuery.
C) Connect an on-premises Apache Hadoop cluster to MySQL and perform ETL.
D) Mount the backups to Google Cloud SQL, and then process the data using Google Cloud Dataproc.
A) Add a node to the MySQL cluster and build an OLAP cube there.
B) Use an ETL tool to load the data from MySQL into Google BigQuery.
C) Connect an on-premises Apache Hadoop cluster to MySQL and perform ETL.
D) Mount the backups to Google Cloud SQL, and then process the data using Google Cloud Dataproc.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
6
Your company is in a highly regulated industry. One of your requirements is to ensure individual users have access only to the minimum amount of information required to do their jobs. You want to enforce this requirement with Google BigQuery. Which three approaches can you take? (Choose three.)
A) Disable writes to certain tables.
B) Restrict access to tables by role.
C) Ensure that the data is encrypted at all times.
D) Restrict BigQuery API access to approved users.
E) Segregate data across multiple tables or databases.
F) Use Google Stackdriver Audit Logging to determine policy violations.
A) Disable writes to certain tables.
B) Restrict access to tables by role.
C) Ensure that the data is encrypted at all times.
D) Restrict BigQuery API access to approved users.
E) Segregate data across multiple tables or databases.
F) Use Google Stackdriver Audit Logging to determine policy violations.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
7
You work for a car manufacturer and have set up a data pipeline using Google Cloud Pub/Sub to capture anomalous sensor events. You are using a push subscription in Cloud Pub/Sub that calls a custom HTTPS endpoint that you have created to take action of these anomalous events as they occur. Your custom HTTPS endpoint keeps getting an inordinate amount of duplicate messages. What is the most likely cause of these duplicate messages?
A) The message body for the sensor event is too large.
B) Your custom endpoint has an out-of-date SSL certificate.
C) The Cloud Pub/Sub topic has too many messages published to it.
D) Your custom endpoint is not acknowledging messages within the acknowledgement deadline.
A) The message body for the sensor event is too large.
B) Your custom endpoint has an out-of-date SSL certificate.
C) The Cloud Pub/Sub topic has too many messages published to it.
D) Your custom endpoint is not acknowledging messages within the acknowledgement deadline.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
8
Business owners at your company have given you a database of bank transactions. Each row contains the user ID, transaction type, transaction location, and transaction amount. They ask you to investigate what type of machine learning can be applied to the data. Which three machine learning applications can you use? (Choose three.)
A) Supervised learning to determine which transactions are most likely to be fraudulent.
B) Unsupervised learning to determine which transactions are most likely to be fraudulent.
C) Clustering to divide the transactions into N categories based on feature similarity.
D) Supervised learning to predict the location of a transaction.
E) Reinforcement learning to predict the location of a transaction.
F) Unsupervised learning to predict the location of a transaction.
A) Supervised learning to determine which transactions are most likely to be fraudulent.
B) Unsupervised learning to determine which transactions are most likely to be fraudulent.
C) Clustering to divide the transactions into N categories based on feature similarity.
D) Supervised learning to predict the location of a transaction.
E) Reinforcement learning to predict the location of a transaction.
F) Unsupervised learning to predict the location of a transaction.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
9
You are working on a sensitive project involving private user data. You have set up a project on Google Cloud Platform to house your work internally. An external consultant is going to assist with coding a complex transformation in a Google Cloud Dataflow pipeline for your project. How should you maintain users' privacy?
A) Grant the consultant the Viewer role on the project.
B) Grant the consultant the Cloud Dataflow Developer role on the project.
C) Create a service account and allow the consultant to log on with it.
D) Create an anonymized sample of the data for the consultant to work with in a different project.
A) Grant the consultant the Viewer role on the project.
B) Grant the consultant the Cloud Dataflow Developer role on the project.
C) Create a service account and allow the consultant to log on with it.
D) Create an anonymized sample of the data for the consultant to work with in a different project.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
10
Your company is migrating their 30-node Apache Hadoop cluster to the cloud. They want to re-use Hadoop jobs they have already created and minimize the management of the cluster as much as possible. They also want to be able to persist data beyond the life of the cluster. What should you do?
A) Create a Google Cloud Dataflow job to process the data.
B) Create a Google Cloud Dataproc cluster that uses persistent disks for HDFS.
C) Create a Hadoop cluster on Google Compute Engine that uses persistent disks.
D) Create a Cloud Dataproc cluster that uses the Google Cloud Storage connector.
E) Create a Hadoop cluster on Google Compute Engine that uses Local SSD disks.
A) Create a Google Cloud Dataflow job to process the data.
B) Create a Google Cloud Dataproc cluster that uses persistent disks for HDFS.
C) Create a Hadoop cluster on Google Compute Engine that uses persistent disks.
D) Create a Cloud Dataproc cluster that uses the Google Cloud Storage connector.
E) Create a Hadoop cluster on Google Compute Engine that uses Local SSD disks.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
11
You have spent a few days loading data from comma-separated values (CSV) files into the Google BigQuery table CLICK_STREAM . The column DT stores the epoch time of click events. For convenience, you chose a simple schema where every field is treated as the STRING type. Now, you want to compute web session durations of users who visit your site, and you want to change its data type to the TIMESTAMP . You want to minimize the migration effort without making future queries computationally expensive. What should you do?
A) Delete the table CLICK_STREAM , and then re-create it such that the column DT is of the TIMESTAMP type. Reload the data. Delete the table , and then re-create it such that the column is of the type. Reload the data.
B) Add a column TS of the TIMESTAMP type to the table CLICK_STREAM , and populate the numeric values from the column TS for each row. Reference the column TS instead of the column DT from now on. Add a column TS of the type to the table , and populate the numeric values from the column for each row. Reference the column instead of the column from now on.
C) Create a view CLICK _ STREAM _ V , where strings from the column DT are cast into TIMESTAMP values. Reference the view CLICK_STREAM_V instead of the table CLICK_STREAM from now on. Create a view CLICK _ STREAM V , where strings from the column are cast into values. Reference the view CLICK_STREAM_V instead of the table
D) Add two columns to the table CLICK STREAM: TS of the TIMESTAMP type and IS_NEW of the BOOLEAN type. Reload all data in append mode. For each appended row, set the value of IS_NEW to true. For future queries, reference the column TS instead of the column DT , with the WHERE clause ensuring that the value of IS_NEW must be true. Add two columns to the table CLICK STREAM: TS type and IS_NEW BOOLEAN type. Reload all data in append mode. For each appended row, set the value of to true. For future queries, reference the column , with the WHERE clause ensuring that the value of must be true.
E) Construct a query to return every row of the table CLICK_STREAM , while using the built-in function to cast strings from the column DT into TIMESTAMP values. Run the query into a destination table NEW_CLICK_STREAM , in which the column TS is the TIMESTAMP type. Reference the table NEW_CLICK_STREAM instead of the table CLICK_STREAM from now on. In the future, new data is loaded into the table NEW_CLICK_STREAM . Construct a query to return every row of the table , while using the built-in function to cast strings from the column into values. Run the query into a destination table NEW_CLICK_STREAM , in which the column is the type. Reference the table from now on. In the future, new data is loaded into the table .
A) Delete the table CLICK_STREAM , and then re-create it such that the column DT is of the TIMESTAMP type. Reload the data. Delete the table , and then re-create it such that the column is of the type. Reload the data.
B) Add a column TS of the TIMESTAMP type to the table CLICK_STREAM , and populate the numeric values from the column TS for each row. Reference the column TS instead of the column DT from now on. Add a column TS of the type to the table , and populate the numeric values from the column for each row. Reference the column instead of the column from now on.
C) Create a view CLICK _ STREAM _ V , where strings from the column DT are cast into TIMESTAMP values. Reference the view CLICK_STREAM_V instead of the table CLICK_STREAM from now on. Create a view CLICK _ STREAM V , where strings from the column are cast into values. Reference the view CLICK_STREAM_V instead of the table
D) Add two columns to the table CLICK STREAM: TS of the TIMESTAMP type and IS_NEW of the BOOLEAN type. Reload all data in append mode. For each appended row, set the value of IS_NEW to true. For future queries, reference the column TS instead of the column DT , with the WHERE clause ensuring that the value of IS_NEW must be true. Add two columns to the table CLICK STREAM: TS type and IS_NEW BOOLEAN type. Reload all data in append mode. For each appended row, set the value of to true. For future queries, reference the column , with the WHERE clause ensuring that the value of must be true.
E) Construct a query to return every row of the table CLICK_STREAM , while using the built-in function to cast strings from the column DT into TIMESTAMP values. Run the query into a destination table NEW_CLICK_STREAM , in which the column TS is the TIMESTAMP type. Reference the table NEW_CLICK_STREAM instead of the table CLICK_STREAM from now on. In the future, new data is loaded into the table NEW_CLICK_STREAM . Construct a query to return every row of the table , while using the built-in function to cast strings from the column into values. Run the query into a destination table NEW_CLICK_STREAM , in which the column is the type. Reference the table from now on. In the future, new data is loaded into the table .
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
12
Flowlogistic Case Study Company Overview Flowlogistic is a leading logistics and supply chain provider. They help businesses throughout the world manage their resources and transport them to their final destination. The company has grown rapidly, expanding their offerings to include rail, truck, aircraft, and oceanic shipping. Company Background The company started as a regional trucking company, and then expanded into other logistics market. Because they have not updated their infrastructure, managing and tracking orders and shipments has become a bottleneck. To improve operations, Flowlogistic developed proprietary technology for tracking shipments in real time at the parcel level. However, they are unable to deploy it because their technology stack, based on Apache Kafka, cannot support the processing volume. In addition, Flowlogistic wants to further analyze their orders and shipments to determine how best to deploy their resources. Solution Concept Flowlogistic wants to implement two concepts using the cloud: Use their proprietary technology in a real-time inventory-tracking system that indicates the location of their loads Perform analytics on all their orders and shipment logs, which contain both structured and unstructured data, to determine how best to deploy resources, which markets to expand info. They also want to use predictive analytics to learn earlier when a shipment will be delayed. Existing Technical Environment Flowlogistic architecture resides in a single data center: Databases 8 physical servers in 2 clusters - SQL Server - user data, inventory, static data 3 physical servers - Cassandra - metadata, tracking messages 10 Kafka servers - tracking message aggregation and batch insert Application servers - customer front end, middleware for order/customs 60 virtual machines across 20 physical servers - Tomcat - Java services - Nginx - static content - Batch servers Storage appliances - iSCSI for virtual machine (VM) hosts - Fibre Channel storage area network (FC SAN) - SQL server storage - Network-attached storage (NAS) image storage, logs, backups 10 Apache Hadoop /Spark servers - Core Data Lake - Data analysis workloads 20 miscellaneous servers - Jenkins, monitoring, bastion hosts, Business Requirements Build a reliable and reproducible environment with scaled panty of production. Aggregate data in a centralized Data Lake for analysis Use historical data to perform predictive analytics on future shipments Accurately track every shipment worldwide using proprietary technology Improve business agility and speed of innovation through rapid provisioning of new resources Analyze and optimize architecture for performance in the cloud Migrate fully to the cloud if all other requirements are met Technical Requirements Handle both streaming and batch data Migrate existing Hadoop workloads Ensure architecture is scalable and elastic to meet the changing demands of the company. Use managed services whenever possible Encrypt data flight and at rest Connect a VPN between the production data center and cloud environment SEO Statement We have grown so quickly that our inability to upgrade our infrastructure is really hampering further growth and efficiency. We are efficient at moving shipments around the world, but we are inefficient at moving data around. We need to organize our information so we can more easily understand where our customers are and what they are shipping. CTO Statement IT has never been a priority for us, so as our data has grown, we have not invested enough in our technology. I have a good staff to manage IT, but they are so busy managing our infrastructure that I cannot get them to do the things that really matter, such as organizing our data, building the analytics, and figuring out how to implement the CFO' s tracking technology. CFO Statement Part of our competitive advantage is that we penalize ourselves for late shipments and deliveries. Knowing where out shipments are at all times has a direct correlation to our bottom line and profitability. Additionally, I don't want to commit capital to building out a server environment. Flowlogistic's CEO wants to gain rapid insight into their customer base so his sales team can be better informed in the field. This team is not very technical, so they've purchased a visualization tool to simplify the creation of BigQuery reports. However, they've been overwhelmed by all the data in the table, and are spending a lot of money on queries trying to find the data they need. You want to solve their problem in the most cost-effective way. What should you do?
A) Export the data into a Google Sheet for virtualization.
B) Create an additional table with only the necessary columns.
C) Create a view on the table to present to the virtualization tool.
D) Create identity and access management (IAM) roles on the appropriate columns, so only they appear in a query.
A) Export the data into a Google Sheet for virtualization.
B) Create an additional table with only the necessary columns.
C) Create a view on the table to present to the virtualization tool.
D) Create identity and access management (IAM) roles on the appropriate columns, so only they appear in a query.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
13
Your company is performing data preprocessing for a learning algorithm in Google Cloud Dataflow. Numerous data logs are being are being generated during this step, and the team wants to analyze them. Due to the dynamic nature of the campaign, the data is growing exponentially every hour. The data scientists have written the following code to read the data for a new key features in the logs. BigQueryIO.Read .named("ReadLogData") .from("clouddataflow-readonly:samples.log_data") You want to improve the performance of this data read. What should you do?
A) Specify the TableReference object in the code. Specify the TableReference object in the code.
B) Use .fromQuery operation to read specific fields from the table. Use .fromQuery operation to read specific fields from the table.
C) Use of both the Google BigQuery TableSchema and TableFieldSchema classes. Use of both the Google BigQuery TableSchema and TableFieldSchema classes.
D) Call a transform that returns TableRow objects, where each element in the PCollection represents a single row in the table. Call a transform that returns TableRow objects, where each element in the PCollection represents a single row in the table.
A) Specify the TableReference object in the code. Specify the TableReference object in the code.
B) Use .fromQuery operation to read specific fields from the table. Use .fromQuery operation to read specific fields from the table.
C) Use of both the Google BigQuery TableSchema and TableFieldSchema classes. Use of both the Google BigQuery TableSchema and TableFieldSchema classes.
D) Call a transform that returns TableRow objects, where each element in the PCollection represents a single row in the table. Call a transform that returns TableRow objects, where each element in the PCollection represents a single row in the table.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
14
You create an important report for your large team in Google Data Studio 360. The report uses Google BigQuery as its data source. You notice that visualizations are not showing data that is less than 1 hour old. What should you do?
A) Disable caching by editing the report settings.
B) Disable caching in BigQuery by editing table details.
C) Refresh your browser tab showing the visualizations.
D) Clear your browser history for the past hour then reload the tab showing the virtualizations.
A) Disable caching by editing the report settings.
B) Disable caching in BigQuery by editing table details.
C) Refresh your browser tab showing the visualizations.
D) Clear your browser history for the past hour then reload the tab showing the virtualizations.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
15
Your company is running their first dynamic campaign, serving different offers by analyzing real-time data during the holiday season. The data scientists are collecting terabytes of data that rapidly grows every hour during their 30-day campaign. They are using Google Cloud Dataflow to preprocess the data and collect the feature (signals) data that is needed for the machine learning model in Google Cloud Bigtable. The team is observing suboptimal performance with reads and writes of their initial load of 10 TB of data. They want to improve this performance while minimizing cost. What should they do?
A) Redefine the schema by evenly distributing reads and writes across the row space of the table.
B) The performance issue should be resolved over time as the site of the BigDate cluster is increased.
C) Redesign the schema to use a single row key to identify values that need to be updated frequently in the cluster.
D) Redesign the schema to use row keys based on numeric IDs that increase sequentially per user viewing the offers.
A) Redefine the schema by evenly distributing reads and writes across the row space of the table.
B) The performance issue should be resolved over time as the site of the BigDate cluster is increased.
C) Redesign the schema to use a single row key to identify values that need to be updated frequently in the cluster.
D) Redesign the schema to use row keys based on numeric IDs that increase sequentially per user viewing the offers.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
16
Your weather app queries a database every 15 minutes to get the current temperature. The frontend is powered by Google App Engine and server millions of users. How should you design the frontend to respond to a database failure?
A) Issue a command to restart the database servers.
B) Retry the query with exponential backoff, up to a cap of 15 minutes.
C) Retry the query every second until it comes back online to minimize staleness of data.
D) Reduce the query frequency to once every hour until the database comes back online.
A) Issue a command to restart the database servers.
B) Retry the query with exponential backoff, up to a cap of 15 minutes.
C) Retry the query every second until it comes back online to minimize staleness of data.
D) Reduce the query frequency to once every hour until the database comes back online.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
17
MJTelco Case Study Company Overview MJTelco is a startup that plans to build networks in rapidly growing, underserved markets around the world. The company has patents for innovative optical communications hardware. Based on these patents, they can create many reliable, high-speed backbone links with inexpensive hardware. Company Background Founded by experienced telecom executives, MJTelco uses technologies originally developed to overcome communications challenges in space. Fundamental to their operation, they need to create a distributed data infrastructure that drives real-time analysis and incorporates machine learning to continuously optimize their topologies. Because their hardware is inexpensive, they plan to overdeploy the network allowing them to account for the impact of dynamic regional politics on location availability and cost. Their management and operations teams are situated all around the globe creating many-to-many relationship between data consumers and provides in their system. After careful consideration, they decided public cloud is the perfect environment to support their needs. Solution Concept MJTelco is running a successful proof-of-concept (PoC) project in its labs. They have two primary needs: Scale and harden their PoC to support significantly more data flows generated when they ramp to more than 50,000 installations. Refine their machine-learning cycles to verify and improve the dynamic models they use to control topology definition. MJTelco will also use three separate operating environments - development/test, staging, and production - to meet the needs of running experiments, deploying new features, and serving production customers. Business Requirements Scale up their production environment with minimal cost, instantiating resources when and where needed in an unpredictable, distributed telecom user community. Ensure security of their proprietary data to protect their leading-edge machine learning and analysis. Provide reliable and timely access to data for analysis from distributed research workers Maintain isolated environments that support rapid iteration of their machine-learning models without affecting their customers. Technical Requirements Ensure secure and efficient transport and storage of telemetry data Rapidly scale instances to support between 10,000 and 100,000 data providers with multiple flows each. Allow analysis and presentation against data tables tracking up to 2 years of data storing approximately 100m records/day Support rapid iteration of monitoring infrastructure focused on awareness of data pipeline problems both in telemetry flows and in production learning cycles. CEO Statement Our business model relies on our patents, analytics and dynamic machine learning. Our inexpensive hardware is organized to be highly reliable, which gives us cost advantages. We need to quickly stabilize our large distributed data pipelines to meet our reliability and capacity commitments. CTO Statement Our public cloud services must operate as advertised. We need resources that scale and keep our data secure. We also need environments in which our data scientists can carefully study and quickly adapt our models. Because we rely on automation to process our data, we also need our development and test environments to work as we iterate. CFO Statement The project is too large for us to maintain the hardware and software required for the data and analysis. Also, we cannot afford to staff an operations team to monitor so many data feeds, so we will rely on automation and infrastructure. Google Cloud's machine learning will allow our quantitative researchers to work on our high-value problems instead of problems with our data pipelines. You need to compose visualizations for operations teams with the following requirements: The report must include telemetry data from all 50,000 installations for the most resent 6 weeks (sampling once every minute). The report must not be more than 3 hours delayed from live data. The actionable report should only show suboptimal links. Most suboptimal links should be sorted to the top. Suboptimal links can be grouped and filtered by regional geography. User response time to load the report must be <5 seconds. Which approach meets the requirements?
A) Load the data into Google Sheets, use formulas to calculate a metric, and use filters/sorting to show only suboptimal links in a table.
B) Load the data into Google BigQuery tables, write Google Apps Script that queries the data, calculates the metric, and shows only suboptimal rows in a table in Google Sheets.
C) Load the data into Google Cloud Datastore tables, write a Google App Engine Application that queries all rows, applies a function to derive the metric, and then renders results in a table using the Google charts and visualization API.
D) Load the data into Google BigQuery tables, write a Google Data Studio 360 report that connects to your data, calculates a metric, and then uses a filter expression to show only suboptimal rows in a table.
A) Load the data into Google Sheets, use formulas to calculate a metric, and use filters/sorting to show only suboptimal links in a table.
B) Load the data into Google BigQuery tables, write Google Apps Script that queries the data, calculates the metric, and shows only suboptimal rows in a table in Google Sheets.
C) Load the data into Google Cloud Datastore tables, write a Google App Engine Application that queries all rows, applies a function to derive the metric, and then renders results in a table using the Google charts and visualization API.
D) Load the data into Google BigQuery tables, write a Google Data Studio 360 report that connects to your data, calculates a metric, and then uses a filter expression to show only suboptimal rows in a table.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
18
Your company built a TensorFlow neutral-network model with a large number of neurons and layers. The model fits well for the training data. However, when tested against new data, it performs poorly. What method can you employ to address this?
A) Threading
B) Serialization
C) Dropout Methods
D) Dimensionality Reduction
A) Threading
B) Serialization
C) Dropout Methods
D) Dimensionality Reduction
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
19
You are building a model to make clothing recommendations. You know a user's fashion preference is likely to change over time, so you build a data pipeline to stream new data back to the model as it becomes available. How should you use this data to train the model?
A) Continuously retrain the model on just the new data.
B) Continuously retrain the model on a combination of existing data and the new data.
C) Train on the existing data while using the new data as your test set.
D) Train on the new data while using the existing data as your test set.
A) Continuously retrain the model on just the new data.
B) Continuously retrain the model on a combination of existing data and the new data.
C) Train on the existing data while using the new data as your test set.
D) Train on the new data while using the existing data as your test set.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
20
You are creating a model to predict housing prices. Due to budget constraints, you must run it on a single resource-constrained virtual machine. Which learning algorithm should you use?
A) Linear regression
B) Logistic classification
C) Recurrent neural network
D) Feedforward neural network
A) Linear regression
B) Logistic classification
C) Recurrent neural network
D) Feedforward neural network
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
21
Your company is loading comma-separated values (CSV) files into Google BigQuery. The data is fully imported successfully; however, the imported data is not matching byte-to-byte to the source file. What is the most likely cause of this problem?
A) The CSV data loaded in BigQuery is not flagged as CSV.
B) The CSV data has invalid rows that were skipped on import.
C) The CSV data loaded in BigQuery is not using BigQuery's default encoding.
D) The CSV data has not gone through an ETL phase before loading into BigQuery.
A) The CSV data loaded in BigQuery is not flagged as CSV.
B) The CSV data has invalid rows that were skipped on import.
C) The CSV data loaded in BigQuery is not using BigQuery's default encoding.
D) The CSV data has not gone through an ETL phase before loading into BigQuery.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
22
You are designing the database schema for a machine learning-based food ordering service that will predict what users want to eat. Here is some of the information you need to store: The user profile: What the user likes and doesn't like to eat The user account information: Name, address, preferred meal times The order information: When orders are made, from where, to whom The database will be used to store all the transactional data of the product. You want to optimize the data schema. Which Google Cloud Platform product should you use?
A) BigQuery
B) Cloud SQL
C) Cloud Bigtable
D) Cloud Datastore
A) BigQuery
B) Cloud SQL
C) Cloud Bigtable
D) Cloud Datastore
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
23
An organization maintains a Google BigQuery dataset that contains tables with user-level data. They want to expose aggregates of this data to other Google Cloud projects, while still controlling access to the user-level data. Additionally, they need to minimize their overall storage cost and ensure the analysis cost for other projects is assigned to those projects. What should they do?
A) Create and share an authorized view that provides the aggregate results.
B) Create and share a new dataset and view that provides the aggregate results.
C) Create and share a new dataset and table that contains the aggregate results.
D) Create dataViewer Identity and Access Management (IAM) roles on the dataset to enable sharing.
A) Create and share an authorized view that provides the aggregate results.
B) Create and share a new dataset and view that provides the aggregate results.
C) Create and share a new dataset and table that contains the aggregate results.
D) Create dataViewer Identity and Access Management (IAM) roles on the dataset to enable sharing.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
24
Your company receives both batch- and stream-based event data. You want to process the data using Google Cloud Dataflow over a predictable time period. However, you realize that in some instances data can arrive late or out of order. How should you design your Cloud Dataflow pipeline to handle data that is late or out of order?
A) Set a single global window to capture all the data.
B) Set sliding windows to capture all the lagged data.
C) Use watermarks and timestamps to capture the lagged data.
D) Ensure every datasource type (stream or batch) has a timestamp, and use the timestamps to define the logic for lagged data.
A) Set a single global window to capture all the data.
B) Set sliding windows to capture all the lagged data.
C) Use watermarks and timestamps to capture the lagged data.
D) Ensure every datasource type (stream or batch) has a timestamp, and use the timestamps to define the logic for lagged data.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
25
You are deploying a new storage system for your mobile application, which is a media streaming service. You decide the best fit is Google Cloud Datastore. You have entities with multiple properties, some of which can take on multiple values. For example, in the entity 'Movie' the property 'actors' and the property 'tags' have multiple values but the property 'date released' does not. A typical query would ask for all movies with actor= ordered by date _ released or all movies with tag=Comedy date_released. How should you avoid a combinatorial explosion in the number of indexes?
A) Manually configure the index in your index config as follows:
B)
C) Set the following in your entity options: exclude_from_indexes = 'actors, tags' Set the following in your entity options: exclude_from_indexes = 'actors, tags'
D) Set the following in your entity options: exclude_from_indexes = 'date_published' exclude_from_indexes = 'date_published'
A) Manually configure the index in your index config as follows:
B)
C) Set the following in your entity options: exclude_from_indexes = 'actors, tags' Set the following in your entity options: exclude_from_indexes = 'actors, tags'
D) Set the following in your entity options: exclude_from_indexes = 'date_published' exclude_from_indexes = 'date_published'
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
26
You have some data, which is shown in the graphic below. The two dimensions are X and Y, and the shade of each dot represents what class it is. You want to classify this data accurately using a linear algorithm. To do this you need to add a synthetic feature. What should the value of that feature be?
A) X^2+Y^2
B) X^2
C) Y^2
D) cos(X)
A) X^2+Y^2
B) X^2
C) Y^2
D) cos(X)
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
27
An online retailer has built their current application on Google App Engine. A new initiative at the company mandates that they extend their application to allow their customers to transact directly via the application. They need to manage their shopping transactions and analyze combined data from multiple datasets using a business intelligence (BI) tool. They want to use only a single database for this purpose. Which Google Cloud database should they choose?
A) BigQuery
B) Cloud SQL
C) Cloud BigTable
D) Cloud Datastore
A) BigQuery
B) Cloud SQL
C) Cloud BigTable
D) Cloud Datastore
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
28
Your company produces 20,000 files every hour. Each data file is formatted as a comma separated values (CSV) file that is less than 4 KB. All files must be ingested on Google Cloud Platform before they can be processed. Your company site has a 200 ms latency to Google Cloud, and your Internet connection bandwidth is limited as 50 Mbps. You currently deploy a secure FTP (SFTP) server on a virtual machine in Google Compute Engine as the data ingestion point. A local SFTP client runs on a dedicated machine to transmit the CSV files as is. The goal is to make reports with data from the previous day available to the executives by 10:00 a.m. each day. This design is barely able to keep up with the current volume, even though the bandwidth utilization is rather low. You are told that due to seasonality, your company expects the number of files to double for the next three months. Which two actions should you take? (Choose two.)
A) Introduce data compression for each file to increase the rate file of file transfer.
B) Contact your internet service provider (ISP) to increase your maximum bandwidth to at least 100 Mbps.
C) Redesign the data ingestion process to use gsutil tool to send the CSV files to a storage bucket in parallel.
D) Assemble 1,000 files into a tape archive (TAR) file. Transmit the TAR files instead, and disassemble the CSV files in the cloud upon receiving them.
E) Create an S3-compatible storage endpoint in your network, and use Google Cloud Storage Transfer Service to transfer on-premices data to the designated storage bucket.
A) Introduce data compression for each file to increase the rate file of file transfer.
B) Contact your internet service provider (ISP) to increase your maximum bandwidth to at least 100 Mbps.
C) Redesign the data ingestion process to use gsutil tool to send the CSV files to a storage bucket in parallel.
D) Assemble 1,000 files into a tape archive (TAR) file. Transmit the TAR files instead, and disassemble the CSV files in the cloud upon receiving them.
E) Create an S3-compatible storage endpoint in your network, and use Google Cloud Storage Transfer Service to transfer on-premices data to the designated storage bucket.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
29
Your analytics team wants to build a simple statistical model to determine which customers are most likely to work with your company again, based on a few different metrics. They want to run the model on Apache Spark, using data housed in Google Cloud Storage, and you have recommended using Google Cloud Dataproc to execute this job. Testing has shown that this workload can run in approximately 30 minutes on a 15-node cluster, outputting the results into Google BigQuery. The plan is to run this workload weekly. How should you optimize the cluster for cost?
A) Migrate the workload to Google Cloud Dataflow
B) Use pre-emptible virtual machines (VMs) for the cluster
C) Use a higher-memory node so that the job runs faster
D) Use SSDs on the worker nodes so that the job can run faster
A) Migrate the workload to Google Cloud Dataflow
B) Use pre-emptible virtual machines (VMs) for the cluster
C) Use a higher-memory node so that the job runs faster
D) Use SSDs on the worker nodes so that the job can run faster
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
30
You have enabled the free integration between Firebase Analytics and Google BigQuery. Firebase now automatically creates a new table daily in BigQuery in the format app_events_YYYYMMDD. You want to query all of the tables for the past 30 days in legacy SQL. What should you do?
A) Use the TABLE_DATE_RANGE function Use the TABLE_DATE_RANGE function
B) Use the WHERE_PARTITIONTIME pseudo column WHERE_PARTITIONTIME pseudo column
C) Use WHERE date BETWEEN YYYY-MM-DD AND YYYY-MM-DD
D) Use SELECT IF.(date >= YYYY-MM-DD AND date <= YYYY-MM-DD
A) Use the TABLE_DATE_RANGE function Use the TABLE_DATE_RANGE function
B) Use the WHERE_PARTITIONTIME pseudo column WHERE_PARTITIONTIME pseudo column
C) Use WHERE date BETWEEN YYYY-MM-DD AND YYYY-MM-DD
D) Use SELECT IF.(date >= YYYY-MM-DD AND date <= YYYY-MM-DD
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
31
You are developing an application that uses a recommendation engine on Google Cloud. Your solution should display new videos to customers based on past views. Your solution needs to generate labels for the entities in videos that the customer has viewed. Your design must be able to provide very fast filtering suggestions based on data from other customer preferences on several TB of data. What should you do?
A) Build and train a complex classification model with Spark MLlib to generate labels and filter the results. Deploy the models using Cloud Dataproc. Call the model from your application.
B) Build and train a classification model with Spark MLlib to generate labels. Build and train a second classification model with Spark MLlib to filter results to match customer preferences. Deploy the models using Cloud Dataproc. Call the models from your application.
C) Build an application that calls the Cloud Video Intelligence API to generate labels. Store data in Cloud Bigtable, and filter the predicted labels to match the user's viewing history to generate preferences.
D) Build an application that calls the Cloud Video Intelligence API to generate labels. Store data in Cloud SQL, and join and filter the predicted labels to match the user's viewing history to generate preferences.
A) Build and train a complex classification model with Spark MLlib to generate labels and filter the results. Deploy the models using Cloud Dataproc. Call the model from your application.
B) Build and train a classification model with Spark MLlib to generate labels. Build and train a second classification model with Spark MLlib to filter results to match customer preferences. Deploy the models using Cloud Dataproc. Call the models from your application.
C) Build an application that calls the Cloud Video Intelligence API to generate labels. Store data in Cloud Bigtable, and filter the predicted labels to match the user's viewing history to generate preferences.
D) Build an application that calls the Cloud Video Intelligence API to generate labels. Store data in Cloud SQL, and join and filter the predicted labels to match the user's viewing history to generate preferences.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
32
Your financial services company is moving to cloud technology and wants to store 50 TB of financial time-series data in the cloud. This data is updated frequently and new data will be streaming in all the time. Your company also wants to move their existing Apache Hadoop jobs to the cloud to get insights into this data. Which product should they use to store the data?
A) Cloud Bigtable
B) Google BigQuery
C) Google Cloud Storage
D) Google Cloud Datastore
A) Cloud Bigtable
B) Google BigQuery
C) Google Cloud Storage
D) Google Cloud Datastore
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
33
Your organization has been collecting and analyzing data in Google BigQuery for 6 months. The majority of the data analyzed is placed in a time-partitioned table named events_partitioned . To reduce the cost of queries, your organization created a view called events , which queries only the last 14 days of data. The view is described in legacy SQL. Next month, existing applications will be connecting to BigQuery to read the data via an ODBC connection. You need to ensure the applications can connect. Which two actions should you take? (Choose two.)
A) Create a new view over events using standard SQL
B) Create a new partitioned table using a standard SQL query
C) Create a new view over events_partitioned using standard SQL
D) Create a service account for the ODBC connection to use for authentication
E) Create a Google Cloud Identity and Access Management (Cloud IAM) role for the ODBC connection and shared "events"
A) Create a new view over events using standard SQL
B) Create a new partitioned table using a standard SQL query
C) Create a new view over events_partitioned using standard SQL
D) Create a service account for the ODBC connection to use for authentication
E) Create a Google Cloud Identity and Access Management (Cloud IAM) role for the ODBC connection and shared "events"
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
34
You are choosing a NoSQL database to handle telemetry data submitted from millions of Internet-of-Things (IoT) devices. The volume of data is growing at 100 TB per year, and each data entry has about 100 attributes. The data processing pipeline does not require atomicity, consistency, isolation, and durability (ACID). However, high availability and low latency are required. You need to analyze the data by querying against individual fields. Which three databases meet your requirements? (Choose three.)
A) Redis
B) HBase
C) MySQL
D) MongoDB
E) Cassandra
F) HDFS with Hive
A) Redis
B) HBase
C) MySQL
D) MongoDB
E) Cassandra
F) HDFS with Hive
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
35
Your company is currently setting up data pipelines for their campaign. For all the Google Cloud Pub/Sub streaming data, one of the important business requirements is to be able to periodically identify the inputs and their timings during their campaign. Engineers have decided to use windowing and transformation in Google Cloud Dataflow for this purpose. However, when testing this feature, they find that the Cloud Dataflow job fails for the all streaming insert. What is the most likely cause of this problem?
A) They have not assigned the timestamp, which causes the job to fail
B) They have not set the triggers to accommodate the data coming in late, which causes the job to fail
C) They have not applied a global windowing function, which causes the job to fail when the pipeline is created
D) They have not applied a non-global windowing function, which causes the job to fail when the pipeline is created
A) They have not assigned the timestamp, which causes the job to fail
B) They have not set the triggers to accommodate the data coming in late, which causes the job to fail
C) They have not applied a global windowing function, which causes the job to fail when the pipeline is created
D) They have not applied a non-global windowing function, which causes the job to fail when the pipeline is created
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
36
You work for a manufacturing plant that batches application log files together into a single log file once a day at 2:00 AM. You have written a Google Cloud Dataflow job to process that log file. You need to make sure the log file in processed once per day as inexpensively as possible. What should you do?
A) Change the processing job to use Google Cloud Dataproc instead.
B) Manually start the Cloud Dataflow job each morning when you get into the office.
C) Create a cron job with Google App Engine Cron Service to run the Cloud Dataflow job.
D) Configure the Cloud Dataflow job as a streaming job so that it processes the log data immediately.
A) Change the processing job to use Google Cloud Dataproc instead.
B) Manually start the Cloud Dataflow job each morning when you get into the office.
C) Create a cron job with Google App Engine Cron Service to run the Cloud Dataflow job.
D) Configure the Cloud Dataflow job as a streaming job so that it processes the log data immediately.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
37
Your infrastructure includes a set of YouTube channels. You have been tasked with creating a process for sending the YouTube channel data to Google Cloud for analysis. You want to design a solution that allows your world-wide marketing teams to perform ANSI SQL and other types of analysis on up-to-date YouTube channels log data. How should you set up the log data transfer into Google Cloud?
A) Use Storage Transfer Service to transfer the offsite backup files to a Cloud Storage Multi-Regional storage bucket as a final destination.
B) Use Storage Transfer Service to transfer the offsite backup files to a Cloud Storage Regional bucket as a final destination.
C) Use BigQuery Data Transfer Service to transfer the offsite backup files to a Cloud Storage Multi-Regional storage bucket as a final destination.
D) Use BigQuery Data Transfer Service to transfer the offsite backup files to a Cloud Storage Regional storage bucket as a final destination.
A) Use Storage Transfer Service to transfer the offsite backup files to a Cloud Storage Multi-Regional storage bucket as a final destination.
B) Use Storage Transfer Service to transfer the offsite backup files to a Cloud Storage Regional bucket as a final destination.
C) Use BigQuery Data Transfer Service to transfer the offsite backup files to a Cloud Storage Multi-Regional storage bucket as a final destination.
D) Use BigQuery Data Transfer Service to transfer the offsite backup files to a Cloud Storage Regional storage bucket as a final destination.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
38
You are implementing security best practices on your data pipeline. Currently, you are manually executing jobs as the Project Owner. You want to automate these jobs by taking nightly batch files containing non-public information from Google Cloud Storage, processing them with a Spark Scala job on a Google Cloud Dataproc cluster, and depositing the results into Google BigQuery. How should you securely run this workload?
A) Restrict the Google Cloud Storage bucket so only you can see the files
B) Grant the Project Owner role to a service account, and run the job with it
C) Use a service account with the ability to read the batch files and to write to BigQuery
D) Use a user account with the Project Viewer role on the Cloud Dataproc cluster to read the batch files and write to BigQuery
A) Restrict the Google Cloud Storage bucket so only you can see the files
B) Grant the Project Owner role to a service account, and run the job with it
C) Use a service account with the ability to read the batch files and to write to BigQuery
D) Use a user account with the Project Viewer role on the Cloud Dataproc cluster to read the batch files and write to BigQuery
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
39
Your company has recently grown rapidly and now ingesting data at a significantly higher rate than it was previously. You manage the daily batch MapReduce analytics jobs in Apache Hadoop. However, the recent increase in data has meant the batch jobs are falling behind. You were asked to recommend ways the development team could increase the responsiveness of the analytics without increasing costs. What should you recommend they do?
A) Rewrite the job in Pig.
B) Rewrite the job in Apache Spark.
C) Increase the size of the Hadoop cluster.
D) Decrease the size of the Hadoop cluster but also rewrite the job in Hive.
A) Rewrite the job in Pig.
B) Rewrite the job in Apache Spark.
C) Increase the size of the Hadoop cluster.
D) Decrease the size of the Hadoop cluster but also rewrite the job in Hive.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
40
You are selecting services to write and transform JSON messages from Cloud Pub/Sub to BigQuery for a data pipeline on Google Cloud. You want to minimize service costs. You also want to monitor and accommodate input data volume that will vary in size with minimal manual intervention. What should you do?
A) Use Cloud Dataproc to run your transformations. Monitor CPU utilization for the cluster. Resize the number of worker nodes in your cluster via the command line.
B) Use Cloud Dataproc to run your transformations. Use the diagnose command to generate an operational output archive. Locate the bottleneck and adjust cluster resources. Use Cloud Dataproc to run your transformations. Use the diagnose command to generate an operational output archive. Locate the bottleneck and adjust cluster resources.
C) Use Cloud Dataflow to run your transformations. Monitor the job system lag with Stackdriver. Use the default autoscaling setting for worker instances.
D) Use Cloud Dataflow to run your transformations. Monitor the total execution time for a sampling of jobs. Configure the job to use non-default Compute Engine machine types when needed.
A) Use Cloud Dataproc to run your transformations. Monitor CPU utilization for the cluster. Resize the number of worker nodes in your cluster via the command line.
B) Use Cloud Dataproc to run your transformations. Use the diagnose command to generate an operational output archive. Locate the bottleneck and adjust cluster resources. Use Cloud Dataproc to run your transformations. Use the diagnose command to generate an operational output archive. Locate the bottleneck and adjust cluster resources.
C) Use Cloud Dataflow to run your transformations. Monitor the job system lag with Stackdriver. Use the default autoscaling setting for worker instances.
D) Use Cloud Dataflow to run your transformations. Monitor the total execution time for a sampling of jobs. Configure the job to use non-default Compute Engine machine types when needed.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
41
MJTelco Case Study Company Overview MJTelco is a startup that plans to build networks in rapidly growing, underserved markets around the world. The company has patents for innovative optical communications hardware. Based on these patents, they can create many reliable, high-speed backbone links with inexpensive hardware. Company Background Founded by experienced telecom executives, MJTelco uses technologies originally developed to overcome communications challenges in space. Fundamental to their operation, they need to create a distributed data infrastructure that drives real-time analysis and incorporates machine learning to continuously optimize their topologies. Because their hardware is inexpensive, they plan to overdeploy the network allowing them to account for the impact of dynamic regional politics on location availability and cost. Their management and operations teams are situated all around the globe creating many-to-many relationship between data consumers and provides in their system. After careful consideration, they decided public cloud is the perfect environment to support their needs. Solution Concept MJTelco is running a successful proof-of-concept (PoC) project in its labs. They have two primary needs: Scale and harden their PoC to support significantly more data flows generated when they ramp to more than 50,000 installations. Refine their machine-learning cycles to verify and improve the dynamic models they use to control topology definition. MJTelco will also use three separate operating environments - development/test, staging, and production - to meet the needs of running experiments, deploying new features, and serving production customers. Business Requirements Scale up their production environment with minimal cost, instantiating resources when and where needed in an unpredictable, distributed telecom user community. Ensure security of their proprietary data to protect their leading-edge machine learning and analysis. Provide reliable and timely access to data for analysis from distributed research workers Maintain isolated environments that support rapid iteration of their machine-learning models without affecting their customers. Technical Requirements Ensure secure and efficient transport and storage of telemetry data Rapidly scale instances to support between 10,000 and 100,000 data providers with multiple flows each. Allow analysis and presentation against data tables tracking up to 2 years of data storing approximately 100m records/day Support rapid iteration of monitoring infrastructure focused on awareness of data pipeline problems both in telemetry flows and in production learning cycles. CEO Statement Our business model relies on our patents, analytics and dynamic machine learning. Our inexpensive hardware is organized to be highly reliable, which gives us cost advantages. We need to quickly stabilize our large distributed data pipelines to meet our reliability and capacity commitments. CTO Statement Our public cloud services must operate as advertised. We need resources that scale and keep our data secure. We also need environments in which our data scientists can carefully study and quickly adapt our models. Because we rely on automation to process our data, we also need our development and test environments to work as we iterate. CFO Statement The project is too large for us to maintain the hardware and software required for the data and analysis. Also, we cannot afford to staff an operations team to monitor so many data feeds, so we will rely on automation and infrastructure. Google Cloud's machine learning will allow our quantitative researchers to work on our high-value problems instead of problems with our data pipelines. You create a new report for your large team in Google Data Studio 360. The report uses Google BigQuery as its data source. It is company policy to ensure employees can view only the data associated with their region, so you create and populate a table for each region. You need to enforce the regional access policy to the data. Which two actions should you take? (Choose two.)
A) Ensure all the tables are included in global dataset.
B) Ensure each table is included in a dataset for a region.
C) Adjust the settings for each table to allow a related region-based security group view access.
D) Adjust the settings for each view to allow a related region-based security group view access.
E) Adjust the settings for each dataset to allow a related region-based security group view access.
A) Ensure all the tables are included in global dataset.
B) Ensure each table is included in a dataset for a region.
C) Adjust the settings for each table to allow a related region-based security group view access.
D) Adjust the settings for each view to allow a related region-based security group view access.
E) Adjust the settings for each dataset to allow a related region-based security group view access.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
42
Your company has hired a new data scientist who wants to perform complicated analyses across very large datasets stored in Google Cloud Storage and in a Cassandra cluster on Google Compute Engine. The scientist primarily wants to create labelled data sets for machine learning projects, along with some visualization tasks. She reports that her laptop is not powerful enough to perform her tasks and it is slowing her down. You want to help her perform her tasks. What should you do?
A) Run a local version of Jupiter on the laptop.
B) Grant the user access to Google Cloud Shell.
C) Host a visualization tool on a VM on Google Compute Engine.
D) Deploy Google Cloud Datalab to a virtual machine (VM) on Google Compute Engine.
A) Run a local version of Jupiter on the laptop.
B) Grant the user access to Google Cloud Shell.
C) Host a visualization tool on a VM on Google Compute Engine.
D) Deploy Google Cloud Datalab to a virtual machine (VM) on Google Compute Engine.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
43
Your company's on-premises Apache Hadoop servers are approaching end-of-life, and IT has decided to migrate the cluster to Google Cloud Dataproc. A like-for-like migration of the cluster would require 50 TB of Google Persistent Disk per node. The CIO is concerned about the cost of using that much block storage. You want to minimize the storage cost of the migration. What should you do?
A) Put the data into Google Cloud Storage.
B) Use preemptible virtual machines (VMs) for the Cloud Dataproc cluster.
C) Tune the Cloud Dataproc cluster so that there is just enough disk for all data.
D) Migrate some of the cold data into Google Cloud Storage, and keep only the hot data in Persistent Disk.
A) Put the data into Google Cloud Storage.
B) Use preemptible virtual machines (VMs) for the Cloud Dataproc cluster.
C) Tune the Cloud Dataproc cluster so that there is just enough disk for all data.
D) Migrate some of the cold data into Google Cloud Storage, and keep only the hot data in Persistent Disk.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
44
Government regulations in your industry mandate that you have to maintain an auditable record of access to certain types of data. Assuming that all expiring logs will be archived correctly, where should you store data that is subject to that mandate?
A) Encrypted on Cloud Storage with user-supplied encryption keys. A separate decryption key will be given to each authorized user.
B) In a BigQuery dataset that is viewable only by authorized personnel, with the Data Access log used to provide the auditability.
C) In Cloud SQL, with separate database user names to each user. The Cloud SQL Admin activity logs will be used to provide the auditability.
D) In a bucket on Cloud Storage that is accessible only by an AppEngine service that collects user information and logs the access before providing a link to the bucket.
A) Encrypted on Cloud Storage with user-supplied encryption keys. A separate decryption key will be given to each authorized user.
B) In a BigQuery dataset that is viewable only by authorized personnel, with the Data Access log used to provide the auditability.
C) In Cloud SQL, with separate database user names to each user. The Cloud SQL Admin activity logs will be used to provide the auditability.
D) In a bucket on Cloud Storage that is accessible only by an AppEngine service that collects user information and logs the access before providing a link to the bucket.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
45
Your neural network model is taking days to train. You want to increase the training speed. What can you do?
A) Subsample your test dataset.
B) Subsample your training dataset.
C) Increase the number of input features to your model.
D) Increase the number of layers in your neural network.
A) Subsample your test dataset.
B) Subsample your training dataset.
C) Increase the number of input features to your model.
D) Increase the number of layers in your neural network.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
46
Flowlogistic Case Study Company Overview Flowlogistic is a leading logistics and supply chain provider. They help businesses throughout the world manage their resources and transport them to their final destination. The company has grown rapidly, expanding their offerings to include rail, truck, aircraft, and oceanic shipping. Company Background The company started as a regional trucking company, and then expanded into other logistics market. Because they have not updated their infrastructure, managing and tracking orders and shipments has become a bottleneck. To improve operations, Flowlogistic developed proprietary technology for tracking shipments in real time at the parcel level. However, they are unable to deploy it because their technology stack, based on Apache Kafka, cannot support the processing volume. In addition, Flowlogistic wants to further analyze their orders and shipments to determine how best to deploy their resources. Solution Concept Flowlogistic wants to implement two concepts using the cloud: Use their proprietary technology in a real-time inventory-tracking system that indicates the location of their loads Perform analytics on all their orders and shipment logs, which contain both structured and unstructured data, to determine how best to deploy resources, which markets to expand info. They also want to use predictive analytics to learn earlier when a shipment will be delayed. Existing Technical Environment Flowlogistic architecture resides in a single data center: Databases 8 physical servers in 2 clusters - SQL Server - user data, inventory, static data 3 physical servers - Cassandra - metadata, tracking messages 10 Kafka servers - tracking message aggregation and batch insert Application servers - customer front end, middleware for order/customs 60 virtual machines across 20 physical servers - Tomcat - Java services - Nginx - static content - Batch servers Storage appliances - iSCSI for virtual machine (VM) hosts - Fibre Channel storage area network (FC SAN) - SQL server storage - Network-attached storage (NAS) image storage, logs, backups 10 Apache Hadoop /Spark servers - Core Data Lake - Data analysis workloads 20 miscellaneous servers - Jenkins, monitoring, bastion hosts, Business Requirements Build a reliable and reproducible environment with scaled panty of production. Aggregate data in a centralized Data Lake for analysis Use historical data to perform predictive analytics on future shipments Accurately track every shipment worldwide using proprietary technology Improve business agility and speed of innovation through rapid provisioning of new resources Analyze and optimize architecture for performance in the cloud Migrate fully to the cloud if all other requirements are met Technical Requirements Handle both streaming and batch data Migrate existing Hadoop workloads Ensure architecture is scalable and elastic to meet the changing demands of the company. Use managed services whenever possible Encrypt data flight and at rest Connect a VPN between the production data center and cloud environment SEO Statement We have grown so quickly that our inability to upgrade our infrastructure is really hampering further growth and efficiency. We are efficient at moving shipments around the world, but we are inefficient at moving data around. We need to organize our information so we can more easily understand where our customers are and what they are shipping. CTO Statement IT has never been a priority for us, so as our data has grown, we have not invested enough in our technology. I have a good staff to manage IT, but they are so busy managing our infrastructure that I cannot get them to do the things that really matter, such as organizing our data, building the analytics, and figuring out how to implement the CFO' s tracking technology. CFO Statement Part of our competitive advantage is that we penalize ourselves for late shipments and deliveries. Knowing where out shipments are at all times has a direct correlation to our bottom line and profitability. Additionally, I don't want to commit capital to building out a server environment. Flowlogistic is rolling out their real-time inventory tracking system. The tracking devices will all send package-tracking messages, which will now go to a single Google Cloud Pub/Sub topic instead of the Apache Kafka cluster. A subscriber application will then process the messages for real-time reporting and store them in Google BigQuery for historical analysis. You want to ensure the package data can be analyzed over time. Which approach should you take?
A) Attach the timestamp on each message in the Cloud Pub/Sub subscriber application as they are received.
B) Attach the timestamp and Package ID on the outbound message from each publisher device as they are sent to Clod Pub/Sub.
C) Use the NOW () function in BigQuery to record the event's time.
D) Use the automatically generated timestamp from Cloud Pub/Sub to order the data.
A) Attach the timestamp on each message in the Cloud Pub/Sub subscriber application as they are received.
B) Attach the timestamp and Package ID on the outbound message from each publisher device as they are sent to Clod Pub/Sub.
C) Use the NOW () function in BigQuery to record the event's time.
D) Use the automatically generated timestamp from Cloud Pub/Sub to order the data.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
47
You are training a spam classifier. You notice that you are overfitting the training data. Which three actions can you take to resolve this problem? (Choose three.)
A) Get more training examples
B) Reduce the number of training examples
C) Use a smaller set of features
D) Use a larger set of features
E) Increase the regularization parameters
F) Decrease the regularization parameters
A) Get more training examples
B) Reduce the number of training examples
C) Use a smaller set of features
D) Use a larger set of features
E) Increase the regularization parameters
F) Decrease the regularization parameters
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
48
You designed a database for patient records as a pilot project to cover a few hundred patients in three clinics. Your design used a single database table to represent all patients and their visits, and you used self-joins to generate reports. The server resource utilization was at 50%. Since then, the scope of the project has expanded. The database must now store 100 times more patient records. You can no longer run the reports, because they either take too long or they encounter errors with insufficient compute resources. How should you adjust the database design?
A) Add capacity (memory and disk space) to the database server by the order of 200.
B) Shard the tables into smaller ones based on date ranges, and only generate reports with prespecified date ranges.
C) Normalize the master patient-record table into the patient table and the visits table, and create other necessary tables to avoid self-join.
D) Partition the table into smaller tables, with one for each clinic. Run queries against the smaller table pairs, and use unions for consolidated reports.
A) Add capacity (memory and disk space) to the database server by the order of 200.
B) Shard the tables into smaller ones based on date ranges, and only generate reports with prespecified date ranges.
C) Normalize the master patient-record table into the patient table and the visits table, and create other necessary tables to avoid self-join.
D) Partition the table into smaller tables, with one for each clinic. Run queries against the smaller table pairs, and use unions for consolidated reports.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
49
Your company handles data processing for a number of different clients. Each client prefers to use their own suite of analytics tools, with some allowing direct query access via Google BigQuery. You need to secure the data so that clients cannot see each other's data. You want to ensure appropriate access to the data. Which three steps should you take? (Choose three.)
A) Load data into different partitions.
B) Load data into a different dataset for each client.
C) Put each client's BigQuery dataset into a different table.
D) Restrict a client's dataset to approved users.
E) Only allow a service account to access the datasets.
F) Use the appropriate identity and access management (IAM) roles for each client's users.
A) Load data into different partitions.
B) Load data into a different dataset for each client.
C) Put each client's BigQuery dataset into a different table.
D) Restrict a client's dataset to approved users.
E) Only allow a service account to access the datasets.
F) Use the appropriate identity and access management (IAM) roles for each client's users.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
50
Your software uses a simple JSON format for all messages. These messages are published to Google Cloud Pub/Sub, then processed with Google Cloud Dataflow to create a real-time dashboard for the CFO. During testing, you notice that some messages are missing in the dashboard. You check the logs, and all messages are being published to Cloud Pub/Sub successfully. What should you do next?
A) Check the dashboard application to see if it is not displaying correctly.
B) Run a fixed dataset through the Cloud Dataflow pipeline and analyze the output.
C) Use Google Stackdriver Monitoring on Cloud Pub/Sub to find the missing messages.
D) Switch Cloud Dataflow to pull messages from Cloud Pub/Sub instead of Cloud Pub/Sub pushing messages to Cloud Dataflow.
A) Check the dashboard application to see if it is not displaying correctly.
B) Run a fixed dataset through the Cloud Dataflow pipeline and analyze the output.
C) Use Google Stackdriver Monitoring on Cloud Pub/Sub to find the missing messages.
D) Switch Cloud Dataflow to pull messages from Cloud Pub/Sub instead of Cloud Pub/Sub pushing messages to Cloud Dataflow.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
51
You want to use Google Stackdriver Logging to monitor Google BigQuery usage. You need an instant notification to be sent to your monitoring tool when new data is appended to a certain table using an insert job, but you do not want to receive notifications for other tables. What should you do?
A) Make a call to the Stackdriver API to list all logs, and apply an advanced filter.
B) In the Stackdriver logging admin interface, and enable a log sink export to BigQuery.
C) In the Stackdriver logging admin interface, enable a log sink export to Google Cloud Pub/Sub, and subscribe to the topic from your monitoring tool.
D) Using the Stackdriver API, create a project sink with advanced log filter to export to Pub/Sub, and subscribe to the topic from your monitoring tool.
A) Make a call to the Stackdriver API to list all logs, and apply an advanced filter.
B) In the Stackdriver logging admin interface, and enable a log sink export to BigQuery.
C) In the Stackdriver logging admin interface, enable a log sink export to Google Cloud Pub/Sub, and subscribe to the topic from your monitoring tool.
D) Using the Stackdriver API, create a project sink with advanced log filter to export to Pub/Sub, and subscribe to the topic from your monitoring tool.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
52
You are using Google BigQuery as your data warehouse. Your users report that the following simple query is running very slowly, no matter when they run the query: SELECT country, state, city FROM [myproject:mydataset.mytable] GROUP BY country You check the query plan for the query and see the following output in the Read section of Stage:1: What is the most likely cause of the delay for this query?
A) Users are running too many concurrent queries in the system
B) The [myproject:mydataset.mytable] table has too many partitions The [myproject:mydataset.mytable] table has too many partitions
C) Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values
D) Most rows in the [myproject:mydataset.mytable] table have the same value in the country column, causing data skew Most rows in the table have the same value in the country column, causing data skew
What is the most likely cause of the delay for this query?A) Users are running too many concurrent queries in the system
B) The [myproject:mydataset.mytable] table has too many partitions The [myproject:mydataset.mytable] table has too many partitions
C) Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values Either the state or the city columns in the [myproject:mydataset.mytable] table have too many NULL values
D) Most rows in the [myproject:mydataset.mytable] table have the same value in the country column, causing data skew Most rows in the table have the same value in the country column, causing data skew
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
53
You are deploying 10,000 new Internet of Things devices to collect temperature data in your warehouses globally. You need to process, store and analyze these very large datasets in real time. What should you do?
A) Send the data to Google Cloud Datastore and then export to BigQuery.
B) Send the data to Google Cloud Pub/Sub, stream Cloud Pub/Sub to Google Cloud Dataflow, and store the data in Google BigQuery.
C) Send the data to Cloud Storage and then spin up an Apache Hadoop cluster as needed in Google Cloud Dataproc whenever analysis is required.
D) Export logs in batch to Google Cloud Storage and then spin up a Google Cloud SQL instance, import the data from Cloud Storage, and run an analysis as needed.
A) Send the data to Google Cloud Datastore and then export to BigQuery.
B) Send the data to Google Cloud Pub/Sub, stream Cloud Pub/Sub to Google Cloud Dataflow, and store the data in Google BigQuery.
C) Send the data to Cloud Storage and then spin up an Apache Hadoop cluster as needed in Google Cloud Dataproc whenever analysis is required.
D) Export logs in batch to Google Cloud Storage and then spin up a Google Cloud SQL instance, import the data from Cloud Storage, and run an analysis as needed.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
54
Flowlogistic Case Study Company Overview Flowlogistic is a leading logistics and supply chain provider. They help businesses throughout the world manage their resources and transport them to their final destination. The company has grown rapidly, expanding their offerings to include rail, truck, aircraft, and oceanic shipping. Company Background The company started as a regional trucking company, and then expanded into other logistics market. Because they have not updated their infrastructure, managing and tracking orders and shipments has become a bottleneck. To improve operations, Flowlogistic developed proprietary technology for tracking shipments in real time at the parcel level. However, they are unable to deploy it because their technology stack, based on Apache Kafka, cannot support the processing volume. In addition, Flowlogistic wants to further analyze their orders and shipments to determine how best to deploy their resources. Solution Concept Flowlogistic wants to implement two concepts using the cloud: Use their proprietary technology in a real-time inventory-tracking system that indicates the location of their loads Perform analytics on all their orders and shipment logs, which contain both structured and unstructured data, to determine how best to deploy resources, which markets to expand info. They also want to use predictive analytics to learn earlier when a shipment will be delayed. Existing Technical Environment Flowlogistic architecture resides in a single data center: Databases 8 physical servers in 2 clusters - SQL Server - user data, inventory, static data 3 physical servers - Cassandra - metadata, tracking messages 10 Kafka servers - tracking message aggregation and batch insert Application servers - customer front end, middleware for order/customs 60 virtual machines across 20 physical servers - Tomcat - Java services - Nginx - static content - Batch servers Storage appliances - iSCSI for virtual machine (VM) hosts - Fibre Channel storage area network (FC SAN) - SQL server storage - Network-attached storage (NAS) image storage, logs, backups 10 Apache Hadoop /Spark servers - Core Data Lake - Data analysis workloads 20 miscellaneous servers - Jenkins, monitoring, bastion hosts, Business Requirements Build a reliable and reproducible environment with scaled panty of production. Aggregate data in a centralized Data Lake for analysis Use historical data to perform predictive analytics on future shipments Accurately track every shipment worldwide using proprietary technology Improve business agility and speed of innovation through rapid provisioning of new resources Analyze and optimize architecture for performance in the cloud Migrate fully to the cloud if all other requirements are met Technical Requirements Handle both streaming and batch data Migrate existing Hadoop workloads Ensure architecture is scalable and elastic to meet the changing demands of the company. Use managed services whenever possible Encrypt data flight and at rest Connect a VPN between the production data center and cloud environment SEO Statement We have grown so quickly that our inability to upgrade our infrastructure is really hampering further growth and efficiency. We are efficient at moving shipments around the world, but we are inefficient at moving data around. We need to organize our information so we can more easily understand where our customers are and what they are shipping. CTO Statement IT has never been a priority for us, so as our data has grown, we have not invested enough in our technology. I have a good staff to manage IT, but they are so busy managing our infrastructure that I cannot get them to do the things that really matter, such as organizing our data, building the analytics, and figuring out how to implement the CFO' s tracking technology. CFO Statement Part of our competitive advantage is that we penalize ourselves for late shipments and deliveries. Knowing where out shipments are at all times has a direct correlation to our bottom line and profitability. Additionally, I don't want to commit capital to building out a server environment. Flowlogistic wants to use Google BigQuery as their primary analysis system, but they still have Apache Hadoop and Spark workloads that they cannot move to BigQuery. Flowlogistic does not know how to store the data that is common to both workloads. What should they do?
A) Store the common data in BigQuery as partitioned tables.
B) Store the common data in BigQuery and expose authorized views.
C) Store the common data encoded as Avro in Google Cloud Storage.
D) Store he common data in the HDFS storage for a Google Cloud Dataproc cluster.
A) Store the common data in BigQuery as partitioned tables.
B) Store the common data in BigQuery and expose authorized views.
C) Store the common data encoded as Avro in Google Cloud Storage.
D) Store he common data in the HDFS storage for a Google Cloud Dataproc cluster.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
55
Your company produces 20,000 files every hour. Each data file is formatted as a comma separated values (CSV) file that is less than 4 KB. All files must be ingested on Google Cloud Platform before they can be processed. Your company site has a 200 ms latency to Google Cloud, and your Internet connection bandwidth is limited as 50 Mbps. You currently deploy a secure FTP (SFTP) server on a virtual machine in Google Compute Engine as the data ingestion point. A local SFTP client runs on a dedicated machine to transmit the CSV files as is. The goal is to make reports with data from the previous day available to the executives by 10:00 a.m. each day. This design is barely able to keep up with the current volume, even though the bandwidth utilization is rather low. You are told that due to seasonality, your company expects the number of files to double for the next three months. Which two actions should you take? (Choose two.)
A) Introduce data compression for each file to increase the rate file of file transfer.
B) Contact your internet service provider (ISP) to increase your maximum bandwidth to at least 100 Mbps.
C) Redesign the data ingestion process to use gsutil tool to send the CSV files to a storage bucket in parallel.
D) Assemble 1,000 files into a tape archive (TAR) file. Transmit the TAR files instead, and disassemble the CSV files in the cloud upon receiving them.
E) Create an S3-compatible storage endpoint in your network, and use Google Cloud Storage Transfer Service to transfer on-premises data to the designated storage bucket.
A) Introduce data compression for each file to increase the rate file of file transfer.
B) Contact your internet service provider (ISP) to increase your maximum bandwidth to at least 100 Mbps.
C) Redesign the data ingestion process to use gsutil tool to send the CSV files to a storage bucket in parallel.
D) Assemble 1,000 files into a tape archive (TAR) file. Transmit the TAR files instead, and disassemble the CSV files in the cloud upon receiving them.
E) Create an S3-compatible storage endpoint in your network, and use Google Cloud Storage Transfer Service to transfer on-premises data to the designated storage bucket.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
56
You want to use a database of information about tissue samples to classify future tissue samples as either normal or mutated. You are evaluating an unsupervised anomaly detection method for classifying the tissue samples. Which two characteristic support this method? (Choose two.)
A) There are very few occurrences of mutations relative to normal samples.
B) There are roughly equal occurrences of both normal and mutated samples in the database.
C) You expect future mutations to have different features from the mutated samples in the database.
D) You expect future mutations to have similar features to the mutated samples in the database.
E) You already have labels for which samples are mutated and which are normal in the database.
A) There are very few occurrences of mutations relative to normal samples.
B) There are roughly equal occurrences of both normal and mutated samples in the database.
C) You expect future mutations to have different features from the mutated samples in the database.
D) You expect future mutations to have similar features to the mutated samples in the database.
E) You already have labels for which samples are mutated and which are normal in the database.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
57
You work for an economic consulting firm that helps companies identify economic trends as they happen. As part of your analysis, you use Google BigQuery to correlate customer data with the average prices of the 100 most common goods sold, including bread, gasoline, milk, and others. The average prices of these goods are updated every 30 minutes. You want to make sure this data stays up to date so you can combine it with other data in BigQuery as cheaply as possible. What should you do?
A) Load the data every 30 minutes into a new partitioned table in BigQuery.
B) Store and update the data in a regional Google Cloud Storage bucket and create a federated data source in BigQuery
C) Store the data in Google Cloud Datastore. Use Google Cloud Dataflow to query BigQuery and combine the data programmatically with the data stored in Cloud Datastore
D) Store the data in a file in a regional Google Cloud Storage bucket. Use Cloud Dataflow to query BigQuery and combine the data programmatically with the data stored in Google Cloud Storage.
A) Load the data every 30 minutes into a new partitioned table in BigQuery.
B) Store and update the data in a regional Google Cloud Storage bucket and create a federated data source in BigQuery
C) Store the data in Google Cloud Datastore. Use Google Cloud Dataflow to query BigQuery and combine the data programmatically with the data stored in Cloud Datastore
D) Store the data in a file in a regional Google Cloud Storage bucket. Use Cloud Dataflow to query BigQuery and combine the data programmatically with the data stored in Google Cloud Storage.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
58
Flowlogistic Case Study Company Overview Flowlogistic is a leading logistics and supply chain provider. They help businesses throughout the world manage their resources and transport them to their final destination. The company has grown rapidly, expanding their offerings to include rail, truck, aircraft, and oceanic shipping. Company Background The company started as a regional trucking company, and then expanded into other logistics market. Because they have not updated their infrastructure, managing and tracking orders and shipments has become a bottleneck. To improve operations, Flowlogistic developed proprietary technology for tracking shipments in real time at the parcel level. However, they are unable to deploy it because their technology stack, based on Apache Kafka, cannot support the processing volume. In addition, Flowlogistic wants to further analyze their orders and shipments to determine how best to deploy their resources. Solution Concept Flowlogistic wants to implement two concepts using the cloud: Use their proprietary technology in a real-time inventory-tracking system that indicates the location of their loads Perform analytics on all their orders and shipment logs, which contain both structured and unstructured data, to determine how best to deploy resources, which markets to expand info. They also want to use predictive analytics to learn earlier when a shipment will be delayed. Existing Technical Environment Flowlogistic architecture resides in a single data center: Databases 8 physical servers in 2 clusters - SQL Server - user data, inventory, static data 3 physical servers - Cassandra - metadata, tracking messages 10 Kafka servers - tracking message aggregation and batch insert Application servers - customer front end, middleware for order/customs 60 virtual machines across 20 physical servers - Tomcat - Java services - Nginx - static content - Batch servers Storage appliances - iSCSI for virtual machine (VM) hosts - Fibre Channel storage area network (FC SAN) - SQL server storage - Network-attached storage (NAS) image storage, logs, backups 10 Apache Hadoop /Spark servers - Core Data Lake - Data analysis workloads 20 miscellaneous servers - Jenkins, monitoring, bastion hosts, Business Requirements Build a reliable and reproducible environment with scaled panty of production. Aggregate data in a centralized Data Lake for analysis Use historical data to perform predictive analytics on future shipments Accurately track every shipment worldwide using proprietary technology Improve business agility and speed of innovation through rapid provisioning of new resources Analyze and optimize architecture for performance in the cloud Migrate fully to the cloud if all other requirements are met Technical Requirements Handle both streaming and batch data Migrate existing Hadoop workloads Ensure architecture is scalable and elastic to meet the changing demands of the company. Use managed services whenever possible Encrypt data flight and at rest Connect a VPN between the production data center and cloud environment SEO Statement We have grown so quickly that our inability to upgrade our infrastructure is really hampering further growth and efficiency. We are efficient at moving shipments around the world, but we are inefficient at moving data around. We need to organize our information so we can more easily understand where our customers are and what they are shipping. CTO Statement IT has never been a priority for us, so as our data has grown, we have not invested enough in our technology. I have a good staff to manage IT, but they are so busy managing our infrastructure that I cannot get them to do the things that really matter, such as organizing our data, building the analytics, and figuring out how to implement the CFO' s tracking technology. CFO Statement Part of our competitive advantage is that we penalize ourselves for late shipments and deliveries. Knowing where out shipments are at all times has a direct correlation to our bottom line and profitability. Additionally, I don't want to commit capital to building out a server environment. Flowlogistic's management has determined that the current Apache Kafka servers cannot handle the data volume for their real-time inventory tracking system. You need to build a new system on Google Cloud Platform (GCP) that will feed the proprietary tracking software. The system must be able to ingest data from a variety of global sources, process and query in real-time, and store the data reliably. Which combination of GCP products should you choose?
A) Cloud Pub/Sub, Cloud Dataflow, and Cloud Storage
B) Cloud Pub/Sub, Cloud Dataflow, and Local SSD
C) Cloud Pub/Sub, Cloud SQL, and Cloud Storage
D) Cloud Load Balancing, Cloud Dataflow, and Cloud Storage
A) Cloud Pub/Sub, Cloud Dataflow, and Cloud Storage
B) Cloud Pub/Sub, Cloud Dataflow, and Local SSD
C) Cloud Pub/Sub, Cloud SQL, and Cloud Storage
D) Cloud Load Balancing, Cloud Dataflow, and Cloud Storage
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
59
You work for a large fast food restaurant chain with over 400,000 employees. You store employee information in Google BigQuery in a Users table consisting of a FirstName field and a LastName field. A member of IT is building an application and asks you to modify the schema and data in BigQuery so the application can query a FullName field consisting of the value of the field concatenated with a space, followed by the value of the field for each employee. How can you make that data available while minimizing cost?
A) Create a view in BigQuery that concatenates the FirstName and LastName field values to produce the FullName . Create a view in BigQuery that concatenates the and field values to produce the .
B) Add a new column called FullName to the Users table. Run an UPDATE statement that updates the FullName column for each user with the concatenation of the FirstName and LastName values. Add a new column called to the Users table. Run an UPDATE statement that updates the column for each user with the concatenation of the and values.
C) Create a Google Cloud Dataflow job that queries BigQuery for the entire Users table, concatenates the FirstName value and LastName value for each user, and loads the proper values for FirstName , LastName , and FullName into a new table in BigQuery. Create a Google Cloud Dataflow job that queries BigQuery for the entire table, concatenates the value and value for each user, and loads the proper values for , , and into a new table in BigQuery.
D) Use BigQuery to export the data for the table to a CSV file. Create a Google Cloud Dataproc job to process the CSV file and output a new CSV file containing the proper values for FirstName , LastName and FullName . Run a BigQuery load job to load the new CSV file into BigQuery. Use BigQuery to export the data for the table to a CSV file. Create a Google Cloud Dataproc job to process the CSV file and output a new CSV file containing the proper values for , . Run a BigQuery load job to load the new CSV file into BigQuery.
A) Create a view in BigQuery that concatenates the FirstName and LastName field values to produce the FullName . Create a view in BigQuery that concatenates the and field values to produce the .
B) Add a new column called FullName to the Users table. Run an UPDATE statement that updates the FullName column for each user with the concatenation of the FirstName and LastName values. Add a new column called to the Users table. Run an UPDATE statement that updates the column for each user with the concatenation of the and values.
C) Create a Google Cloud Dataflow job that queries BigQuery for the entire Users table, concatenates the FirstName value and LastName value for each user, and loads the proper values for FirstName , LastName , and FullName into a new table in BigQuery. Create a Google Cloud Dataflow job that queries BigQuery for the entire table, concatenates the value and value for each user, and loads the proper values for , , and into a new table in BigQuery.
D) Use BigQuery to export the data for the table to a CSV file. Create a Google Cloud Dataproc job to process the CSV file and output a new CSV file containing the proper values for FirstName , LastName and FullName . Run a BigQuery load job to load the new CSV file into BigQuery. Use BigQuery to export the data for the table to a CSV file. Create a Google Cloud Dataproc job to process the CSV file and output a new CSV file containing the proper values for , . Run a BigQuery load job to load the new CSV file into BigQuery.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
60
Your company maintains a hybrid deployment with GCP, where analytics are performed on your anonymized customer data. The data are imported to Cloud Storage from your data center through parallel uploads to a data transfer server running on GCP. Management informs you that the daily transfers take too long and have asked you to fix the problem. You want to maximize transfer speeds. Which action should you take?
A) Increase the CPU size on your server.
B) Increase the size of the Google Persistent Disk on your server.
C) Increase your network bandwidth from your datacenter to GCP.
D) Increase your network bandwidth from Compute Engine to Cloud Storage.
A) Increase the CPU size on your server.
B) Increase the size of the Google Persistent Disk on your server.
C) Increase your network bandwidth from your datacenter to GCP.
D) Increase your network bandwidth from Compute Engine to Cloud Storage.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
61
You need to create a near real-time inventory dashboard that reads the main inventory tables in your BigQuery data warehouse. Historical inventory data is stored as inventory balances by item and location. You have several thousand updates to inventory every hour. You want to maximize performance of the dashboard and ensure that the data is accurate. What should you do?
A) Leverage BigQuery UPDATE statements to update the inventory balances as they are changing.
B) Partition the inventory balance table by item to reduce the amount of data scanned with each inventory update.
C) Use the BigQuery streaming the stream changes into a daily inventory movement table. Calculate balances in a view that joins it to the historical inventory balance table. Update the inventory balance table nightly.
D) Use the BigQuery bulk loader to batch load inventory changes into a daily inventory movement table. Calculate balances in a view that joins it to the historical inventory balance table. Update the inventory balance table nightly.
A) Leverage BigQuery UPDATE statements to update the inventory balances as they are changing.
B) Partition the inventory balance table by item to reduce the amount of data scanned with each inventory update.
C) Use the BigQuery streaming the stream changes into a daily inventory movement table. Calculate balances in a view that joins it to the historical inventory balance table. Update the inventory balance table nightly.
D) Use the BigQuery bulk loader to batch load inventory changes into a daily inventory movement table. Calculate balances in a view that joins it to the historical inventory balance table. Update the inventory balance table nightly.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
62
You set up a streaming data insert into a Redis cluster via a Kafka cluster. Both clusters are running on Compute Engine instances. You need to encrypt data at rest with encryption keys that you can create, rotate, and destroy as needed. What should you do?
A) Create a dedicated service account, and use encryption at rest to reference your data stored in your Compute Engine cluster instances as part of your API service calls.
B) Create encryption keys in Cloud Key Management Service. Use those keys to encrypt your data in all of the Compute Engine cluster instances.
C) Create encryption keys locally. Upload your encryption keys to Cloud Key Management Service. Use those keys to encrypt your data in all of the Compute Engine cluster instances.
D) Create encryption keys in Cloud Key Management Service. Reference those keys in your API service calls when accessing the data in your Compute Engine cluster instances.
A) Create a dedicated service account, and use encryption at rest to reference your data stored in your Compute Engine cluster instances as part of your API service calls.
B) Create encryption keys in Cloud Key Management Service. Use those keys to encrypt your data in all of the Compute Engine cluster instances.
C) Create encryption keys locally. Upload your encryption keys to Cloud Key Management Service. Use those keys to encrypt your data in all of the Compute Engine cluster instances.
D) Create encryption keys in Cloud Key Management Service. Reference those keys in your API service calls when accessing the data in your Compute Engine cluster instances.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
63
You are a head of BI at a large enterprise company with multiple business units that each have different priorities and budgets. You use on-demand pricing for BigQuery with a quota of 2K concurrent on-demand slots per project. Users at your organization sometimes don't get slots to execute their query and you need to correct this. You'd like to avoid introducing new projects to your account. What should you do?
A) Convert your batch BQ queries into interactive BQ queries.
B) Create an additional project to overcome the 2K on-demand per-project quota.
C) Switch to flat-rate pricing and establish a hierarchical priority model for your projects.
D) Increase the amount of concurrent slots per project at the Quotas page at the Cloud Console.
A) Convert your batch BQ queries into interactive BQ queries.
B) Create an additional project to overcome the 2K on-demand per-project quota.
C) Switch to flat-rate pricing and establish a hierarchical priority model for your projects.
D) Increase the amount of concurrent slots per project at the Quotas page at the Cloud Console.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
64
You are designing an Apache Beam pipeline to enrich data from Cloud Pub/Sub with static reference data from BigQuery. The reference data is small enough to fit in memory on a single worker. The pipeline should write enriched results to BigQuery for analysis. Which job type and transforms should this pipeline use?
A) Batch job, PubSubIO, side-inputs
B) Streaming job, PubSubIO, JdbcIO, side-outputs
C) Streaming job, PubSubIO, BigQueryIO, side-inputs
D) Streaming job, PubSubIO, BigQueryIO, side-outputs
A) Batch job, PubSubIO, side-inputs
B) Streaming job, PubSubIO, JdbcIO, side-outputs
C) Streaming job, PubSubIO, BigQueryIO, side-inputs
D) Streaming job, PubSubIO, BigQueryIO, side-outputs
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
65
MJTelco Case Study Company Overview MJTelco is a startup that plans to build networks in rapidly growing, underserved markets around the world. The company has patents for innovative optical communications hardware. Based on these patents, they can create many reliable, high-speed backbone links with inexpensive hardware. Company Background Founded by experienced telecom executives, MJTelco uses technologies originally developed to overcome communications challenges in space. Fundamental to their operation, they need to create a distributed data infrastructure that drives real-time analysis and incorporates machine learning to continuously optimize their topologies. Because their hardware is inexpensive, they plan to overdeploy the network allowing them to account for the impact of dynamic regional politics on location availability and cost. Their management and operations teams are situated all around the globe creating many-to-many relationship between data consumers and provides in their system. After careful consideration, they decided public cloud is the perfect environment to support their needs. Solution Concept MJTelco is running a successful proof-of-concept (PoC) project in its labs. They have two primary needs: Scale and harden their PoC to support significantly more data flows generated when they ramp to more than 50,000 installations. Refine their machine-learning cycles to verify and improve the dynamic models they use to control topology definition. MJTelco will also use three separate operating environments - development/test, staging, and production - to meet the needs of running experiments, deploying new features, and serving production customers. Business Requirements Scale up their production environment with minimal cost, instantiating resources when and where needed in an unpredictable, distributed telecom user community. Ensure security of their proprietary data to protect their leading-edge machine learning and analysis. Provide reliable and timely access to data for analysis from distributed research workers Maintain isolated environments that support rapid iteration of their machine-learning models without affecting their customers. Technical Requirements Ensure secure and efficient transport and storage of telemetry data Rapidly scale instances to support between 10,000 and 100,000 data providers with multiple flows each. Allow analysis and presentation against data tables tracking up to 2 years of data storing approximately 100m records/day Support rapid iteration of monitoring infrastructure focused on awareness of data pipeline problems both in telemetry flows and in production learning cycles. CEO Statement Our business model relies on our patents, analytics and dynamic machine learning. Our inexpensive hardware is organized to be highly reliable, which gives us cost advantages. We need to quickly stabilize our large distributed data pipelines to meet our reliability and capacity commitments. CTO Statement Our public cloud services must operate as advertised. We need resources that scale and keep our data secure. We also need environments in which our data scientists can carefully study and quickly adapt our models. Because we rely on automation to process our data, we also need our development and test environments to work as we iterate. CFO Statement The project is too large for us to maintain the hardware and software required for the data and analysis. Also, we cannot afford to staff an operations team to monitor so many data feeds, so we will rely on automation and infrastructure. Google Cloud's machine learning will allow our quantitative researchers to work on our high-value problems instead of problems with our data pipelines. You need to compose visualization for operations teams with the following requirements: Telemetry must include data from all 50,000 installations for the most recent 6 weeks (sampling once every minute) The report must not be more than 3 hours delayed from live data. The actionable report should only show suboptimal links. Most suboptimal links should be sorted to the top. Suboptimal links can be grouped and filtered by regional geography. User response time to load the report must be <5 seconds. You create a data source to store the last 6 weeks of data, and create visualizations that allow viewers to see multiple date ranges, distinct geographic regions, and unique installation types. You always show the latest data without any changes to your visualizations. You want to avoid creating and updating new visualizations each month. What should you do?
A) Look through the current data and compose a series of charts and tables, one for each possible combination of criteria.
B) Look through the current data and compose a small set of generalized charts and tables bound to criteria filters that allow value selection.
C) Export the data to a spreadsheet, compose a series of charts and tables, one for each possible combination of criteria, and spread them across multiple tabs.
D) Load the data into relational database tables, write a Google App Engine application that queries all rows, summarizes the data across each criteria, and then renders results using the Google Charts and visualization API.
A) Look through the current data and compose a series of charts and tables, one for each possible combination of criteria.
B) Look through the current data and compose a small set of generalized charts and tables bound to criteria filters that allow value selection.
C) Export the data to a spreadsheet, compose a series of charts and tables, one for each possible combination of criteria, and spread them across multiple tabs.
D) Load the data into relational database tables, write a Google App Engine application that queries all rows, summarizes the data across each criteria, and then renders results using the Google Charts and visualization API.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
66
You've migrated a Hadoop job from an on-prem cluster to dataproc and GCS. Your Spark job is a complicated analytical workload that consists of many shuffing operations and initial data are parquet files (on average 200-400 MB size each). You see some degradation in performance after the migration to Dataproc, so you'd like to optimize for it. You need to keep in mind that your organization is very cost-sensitive, so you'd like to continue using Dataproc on preemptibles (with 2 non-preemptible workers only) for this workload. What should you do?
A) Increase the size of your parquet files to ensure them to be 1 GB minimum.
B) Switch to TFRecords formats (appr. 200MB per file) instead of parquet files.
C) Switch from HDDs to SSDs, copy initial data from GCS to HDFS, run the Spark job and copy results back to GCS.
D) Switch from HDDs to SSDs, override the preemptible VMs configuration to increase the boot disk size.
A) Increase the size of your parquet files to ensure them to be 1 GB minimum.
B) Switch to TFRecords formats (appr. 200MB per file) instead of parquet files.
C) Switch from HDDs to SSDs, copy initial data from GCS to HDFS, run the Spark job and copy results back to GCS.
D) Switch from HDDs to SSDs, override the preemptible VMs configuration to increase the boot disk size.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
67
You used Cloud Dataprep to create a recipe on a sample of data in a BigQuery table. You want to reuse this recipe on a daily upload of data with the same schema, after the load job with variable execution time completes. What should you do?
A) Create a cron schedule in Cloud Dataprep.
B) Create an App Engine cron job to schedule the execution of the Cloud Dataprep job.
C) Export the recipe as a Cloud Dataprep template, and create a job in Cloud Scheduler.
D) Export the Cloud Dataprep job as a Cloud Dataflow template, and incorporate it into a Cloud Composer job.
A) Create a cron schedule in Cloud Dataprep.
B) Create an App Engine cron job to schedule the execution of the Cloud Dataprep job.
C) Export the recipe as a Cloud Dataprep template, and create a job in Cloud Scheduler.
D) Export the Cloud Dataprep job as a Cloud Dataflow template, and incorporate it into a Cloud Composer job.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
68
You launched a new gaming app almost three years ago. You have been uploading log files from the previous day to a separate Google BigQuery table with the table name format LOGS_yyyymmdd. You have been using table wildcard functions to generate daily and monthly reports for all time ranges. Recently, you discovered that some queries that cover long date ranges are exceeding the limit of 1,000 tables and failing. How can you resolve this issue?
A) Convert all daily log tables into date-partitioned tables
B) Convert the sharded tables into a single partitioned table
C) Enable query caching so you can cache data from previous months
D) Create separate views to cover each month, and query from these views
A) Convert all daily log tables into date-partitioned tables
B) Convert the sharded tables into a single partitioned table
C) Enable query caching so you can cache data from previous months
D) Create separate views to cover each month, and query from these views
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
69
You have a requirement to insert minute-resolution data from 50,000 sensors into a BigQuery table. You expect significant growth in data volume and need the data to be available within 1 minute of ingestion for real-time analysis of aggregated trends. What should you do?
A) Use bq load to load a batch of sensor data every 60 seconds. Use bq load to load a batch of sensor data every 60 seconds.
B) Use a Cloud Dataflow pipeline to stream data into the BigQuery table.
C) Use the INSERT statement to insert a batch of data every 60 seconds.
D) Use the MERGE statement to apply updates in batch every 60 seconds.
A) Use bq load to load a batch of sensor data every 60 seconds. Use bq load to load a batch of sensor data every 60 seconds.
B) Use a Cloud Dataflow pipeline to stream data into the BigQuery table.
C) Use the INSERT statement to insert a batch of data every 60 seconds.
D) Use the MERGE statement to apply updates in batch every 60 seconds.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
70
You store historic data in Cloud Storage. You need to perform analytics on the historic data. You want to use a solution to detect invalid data entries and perform data transformations that will not require programming or knowledge of SQL. What should you do?
A) Use Cloud Dataflow with Beam to detect errors and perform transformations.
B) Use Cloud Dataprep with recipes to detect errors and perform transformations.
C) Use Cloud Dataproc with a Hadoop job to detect errors and perform transformations.
D) Use federated tables in BigQuery with queries to detect errors and perform transformations.
A) Use Cloud Dataflow with Beam to detect errors and perform transformations.
B) Use Cloud Dataprep with recipes to detect errors and perform transformations.
C) Use Cloud Dataproc with a Hadoop job to detect errors and perform transformations.
D) Use federated tables in BigQuery with queries to detect errors and perform transformations.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
71
MJTelco Case Study Company Overview MJTelco is a startup that plans to build networks in rapidly growing, underserved markets around the world. The company has patents for innovative optical communications hardware. Based on these patents, they can create many reliable, high-speed backbone links with inexpensive hardware. Company Background Founded by experienced telecom executives, MJTelco uses technologies originally developed to overcome communications challenges in space. Fundamental to their operation, they need to create a distributed data infrastructure that drives real-time analysis and incorporates machine learning to continuously optimize their topologies. Because their hardware is inexpensive, they plan to overdeploy the network allowing them to account for the impact of dynamic regional politics on location availability and cost. Their management and operations teams are situated all around the globe creating many-to-many relationship between data consumers and provides in their system. After careful consideration, they decided public cloud is the perfect environment to support their needs. Solution Concept MJTelco is running a successful proof-of-concept (PoC) project in its labs. They have two primary needs: Scale and harden their PoC to support significantly more data flows generated when they ramp to more than 50,000 installations. Refine their machine-learning cycles to verify and improve the dynamic models they use to control topology definition. MJTelco will also use three separate operating environments - development/test, staging, and production - to meet the needs of running experiments, deploying new features, and serving production customers. Business Requirements Scale up their production environment with minimal cost, instantiating resources when and where needed in an unpredictable, distributed telecom user community. Ensure security of their proprietary data to protect their leading-edge machine learning and analysis. Provide reliable and timely access to data for analysis from distributed research workers Maintain isolated environments that support rapid iteration of their machine-learning models without affecting their customers. Technical Requirements Ensure secure and efficient transport and storage of telemetry data Rapidly scale instances to support between 10,000 and 100,000 data providers with multiple flows each. Allow analysis and presentation against data tables tracking up to 2 years of data storing approximately 100m records/day Support rapid iteration of monitoring infrastructure focused on awareness of data pipeline problems both in telemetry flows and in production learning cycles. CEO Statement Our business model relies on our patents, analytics and dynamic machine learning. Our inexpensive hardware is organized to be highly reliable, which gives us cost advantages. We need to quickly stabilize our large distributed data pipelines to meet our reliability and capacity commitments. CTO Statement Our public cloud services must operate as advertised. We need resources that scale and keep our data secure. We also need environments in which our data scientists can carefully study and quickly adapt our models. Because we rely on automation to process our data, we also need our development and test environments to work as we iterate. CFO Statement The project is too large for us to maintain the hardware and software required for the data and analysis. Also, we cannot afford to staff an operations team to monitor so many data feeds, so we will rely on automation and infrastructure. Google Cloud's machine learning will allow our quantitative researchers to work on our high-value problems instead of problems with our data pipelines. Given the record streams MJTelco is interested in ingesting per day, they are concerned about the cost of Google BigQuery increasing. MJTelco asks you to provide a design solution. They require a single large data table called tracking_table . Additionally, they want to minimize the cost of daily queries while performing fine-grained analysis of each day's events. They also want to use streaming ingestion. What should you do?
A) Create a table called tracking_table and include a DATE column.
B) Create a partitioned table called tracking_table and include a TIMESTAMP column.
C) Create sharded tables for each day following the pattern tracking_table_YYYYMMDD.
D) Create a table called tracking_table with a TIMESTAMP column to represent the day.
A) Create a table called tracking_table and include a DATE column.
B) Create a partitioned table called tracking_table and include a TIMESTAMP column.
C) Create sharded tables for each day following the pattern tracking_table_YYYYMMDD.
D) Create a table called tracking_table with a TIMESTAMP column to represent the day.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
72
You're training a model to predict housing prices based on an available dataset with real estate properties. Your plan is to train a fully connected neural net, and you've discovered that the dataset contains latitude and longtitude of the property. Real estate professionals have told you that the location of the property is highly influential on price, so you'd like to engineer a feature that incorporates this physical dependency. What should you do?
A) Provide latitude and longtitude as input vectors to your neural net.
B) Create a numeric column from a feature cross of latitude and longtitude.
C) Create a feature cross of latitude and longtitude, bucketize at the minute level and use L1 regularization during optimization.
D) Create a feature cross of latitude and longtitude, bucketize it at the minute level and use L2 regularization during optimization.
A) Provide latitude and longtitude as input vectors to your neural net.
B) Create a numeric column from a feature cross of latitude and longtitude.
C) Create a feature cross of latitude and longtitude, bucketize at the minute level and use L1 regularization during optimization.
D) Create a feature cross of latitude and longtitude, bucketize it at the minute level and use L2 regularization during optimization.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
73
Your company needs to upload their historic data to Cloud Storage. The security rules don't allow access from external IPs to their on-premises resources. After an initial upload, they will add new data from existing on-premises applications every day. What should they do?
A) Execute gsutil rsync from the on-premises servers. Execute gsutil rsync from the on-premises servers.
B) Use Cloud Dataflow and write the data to Cloud Storage.
C) Write a job template in Cloud Dataproc to perform the data transfer.
D) Install an FTP server on a Compute Engine VM to receive the files and move them to Cloud Storage.
A) Execute gsutil rsync from the on-premises servers. Execute gsutil rsync from the on-premises servers.
B) Use Cloud Dataflow and write the data to Cloud Storage.
C) Write a job template in Cloud Dataproc to perform the data transfer.
D) Install an FTP server on a Compute Engine VM to receive the files and move them to Cloud Storage.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
74
You need to migrate a 2TB relational database to Google Cloud Platform. You do not have the resources to significantly refactor the application that uses this database and cost to operate is of primary concern. Which service do you select for storing and serving your data?
A) Cloud Spanner
B) Cloud Bigtable
C) Cloud Firestore
D) Cloud SQL
A) Cloud Spanner
B) Cloud Bigtable
C) Cloud Firestore
D) Cloud SQL
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
75
You are designing storage for two relational tables that are part of a 10-TB database on Google Cloud. You want to support transactions that scale horizontally. You also want to optimize data for range queries on non-key columns. What should you do?
A) Use Cloud SQL for storage. Add secondary indexes to support query patterns.
B) Use Cloud SQL for storage. Use Cloud Dataflow to transform data to support query patterns.
C) Use Cloud Spanner for storage. Add secondary indexes to support query patterns.
D) Use Cloud Spanner for storage. Use Cloud Dataflow to transform data to support query patterns.
A) Use Cloud SQL for storage. Add secondary indexes to support query patterns.
B) Use Cloud SQL for storage. Use Cloud Dataflow to transform data to support query patterns.
C) Use Cloud Spanner for storage. Add secondary indexes to support query patterns.
D) Use Cloud Spanner for storage. Use Cloud Dataflow to transform data to support query patterns.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
76
You are designing storage for very large text files for a data pipeline on Google Cloud. You want to support ANSI SQL queries. You also want to support compression and parallel load from the input locations using Google recommended practices. What should you do?
A) Transform text files to compressed Avro using Cloud Dataflow. Use BigQuery for storage and query.
B) Transform text files to compressed Avro using Cloud Dataflow. Use Cloud Storage and BigQuery permanent linked tables for query.
C) Compress text files to gzip using the Grid Computing Tools. Use BigQuery for storage and query.
D) Compress text files to gzip using the Grid Computing Tools. Use Cloud Storage, and then import into Cloud Bigtable for query.
A) Transform text files to compressed Avro using Cloud Dataflow. Use BigQuery for storage and query.
B) Transform text files to compressed Avro using Cloud Dataflow. Use Cloud Storage and BigQuery permanent linked tables for query.
C) Compress text files to gzip using the Grid Computing Tools. Use BigQuery for storage and query.
D) Compress text files to gzip using the Grid Computing Tools. Use Cloud Storage, and then import into Cloud Bigtable for query.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
77
You want to automate execution of a multi-step data pipeline running on Google Cloud. The pipeline includes Cloud Dataproc and Cloud Dataflow jobs that have multiple dependencies on each other. You want to use managed services where possible, and the pipeline will run every day. Which tool should you use?
A) cron
B) Cloud Composer
C) Cloud Scheduler
D) Workflow Templates on Cloud Dataproc
A) cron
B) Cloud Composer
C) Cloud Scheduler
D) Workflow Templates on Cloud Dataproc
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
78
Your globally distributed auction application allows users to bid on items. Occasionally, users place identical bids at nearly identical times, and different application servers process those bids. Each bid event contains the item, amount, user, and timestamp. You want to collate those bid events into a single location in real time to determine which user bid first. What should you do?
A) Create a file on a shared file and have the application servers write all bid events to that file. Process the file with Apache Hadoop to identify which user bid first.
B) Have each application server write the bid events to Cloud Pub/Sub as they occur. Push the events from Cloud Pub/Sub to a custom endpoint that writes the bid event information into Cloud SQL.
C) Set up a MySQL database for each application server to write bid events into. Periodically query each of those distributed MySQL databases and update a master MySQL database with bid event information.
D) Have each application server write the bid events to Google Cloud Pub/Sub as they occur. Use a pull subscription to pull the bid events using Google Cloud Dataflow. Give the bid for each item to the user in the bid event that is processed first.
A) Create a file on a shared file and have the application servers write all bid events to that file. Process the file with Apache Hadoop to identify which user bid first.
B) Have each application server write the bid events to Cloud Pub/Sub as they occur. Push the events from Cloud Pub/Sub to a custom endpoint that writes the bid event information into Cloud SQL.
C) Set up a MySQL database for each application server to write bid events into. Periodically query each of those distributed MySQL databases and update a master MySQL database with bid event information.
D) Have each application server write the bid events to Google Cloud Pub/Sub as they occur. Use a pull subscription to pull the bid events using Google Cloud Dataflow. Give the bid for each item to the user in the bid event that is processed first.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
79
You want to analyze hundreds of thousands of social media posts daily at the lowest cost and with the fewest steps. You have the following requirements: You will batch-load the posts once per day and run them through the Cloud Natural Language API. You will extract topics and sentiment from the posts. You must store the raw posts for archiving and reprocessing. You will create dashboards to be shared with people both inside and outside your organization. You need to store both the data extracted from the API to perform analysis as well as the raw social media posts for historical archiving. What should you do?
A) Store the social media posts and the data extracted from the API in BigQuery.
B) Store the social media posts and the data extracted from the API in Cloud SQL.
C) Store the raw social media posts in Cloud Storage, and write the data extracted from the API into BigQuery.
D) Feed to social media posts into the API directly from the source, and write the extracted data from the API into BigQuery.
A) Store the social media posts and the data extracted from the API in BigQuery.
B) Store the social media posts and the data extracted from the API in Cloud SQL.
C) Store the raw social media posts in Cloud Storage, and write the data extracted from the API into BigQuery.
D) Feed to social media posts into the API directly from the source, and write the extracted data from the API into BigQuery.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
80
You have a data stored in BigQuery. The data in the BigQuery dataset must be highly available. You need to define a storage, backup, and recovery strategy of this data that minimizes cost. How should you configure the BigQuery table?
A) Set the BigQuery dataset to be regional. In the event of an emergency, use a point-in-time snapshot to recover the data.
B) Set the BigQuery dataset to be regional. Create a scheduled query to make copies of the data to tables suffixed with the time of the backup. In the event of an emergency, use the backup copy of the table.
C) Set the BigQuery dataset to be multi-regional. In the event of an emergency, use a point-in-time snapshot to recover the data.
D) Set the BigQuery dataset to be multi-regional. Create a scheduled query to make copies of the data to tables suffixed with the time of the backup. In the event of an emergency, use the backup copy of the table.
A) Set the BigQuery dataset to be regional. In the event of an emergency, use a point-in-time snapshot to recover the data.
B) Set the BigQuery dataset to be regional. Create a scheduled query to make copies of the data to tables suffixed with the time of the backup. In the event of an emergency, use the backup copy of the table.
C) Set the BigQuery dataset to be multi-regional. In the event of an emergency, use a point-in-time snapshot to recover the data.
D) Set the BigQuery dataset to be multi-regional. Create a scheduled query to make copies of the data to tables suffixed with the time of the backup. In the event of an emergency, use the backup copy of the table.
Unlock Deck
Unlock for access to all 256 flashcards in this deck.
Unlock Deck
k this deck
Unlock Deck
Unlock for access to all 256 flashcards in this deck.


