Essay
A bank wants to understand better the details of customers who are likely to default the loan. In order to analyze this, the data from a random sample of 200 customers are given below:
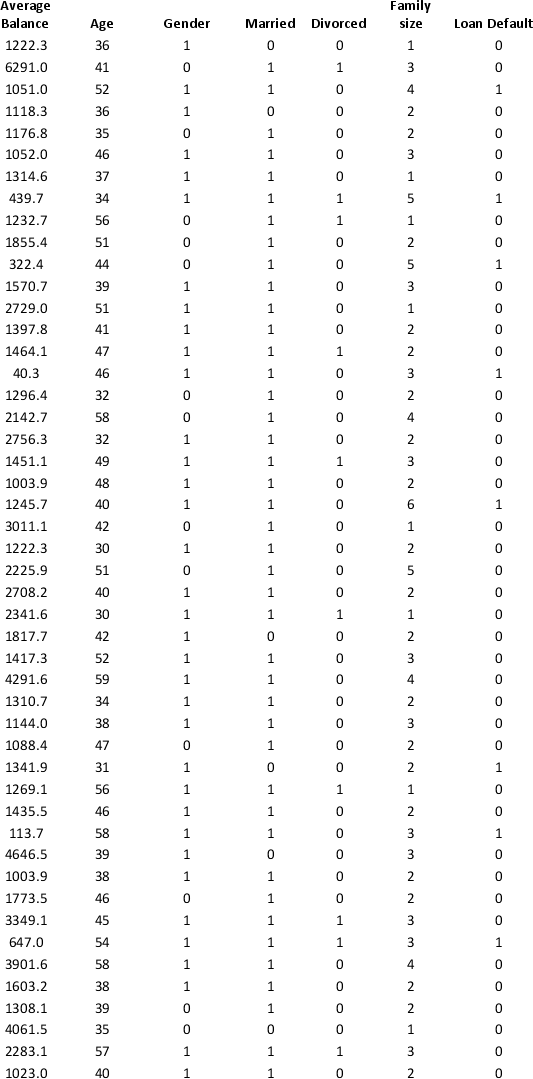
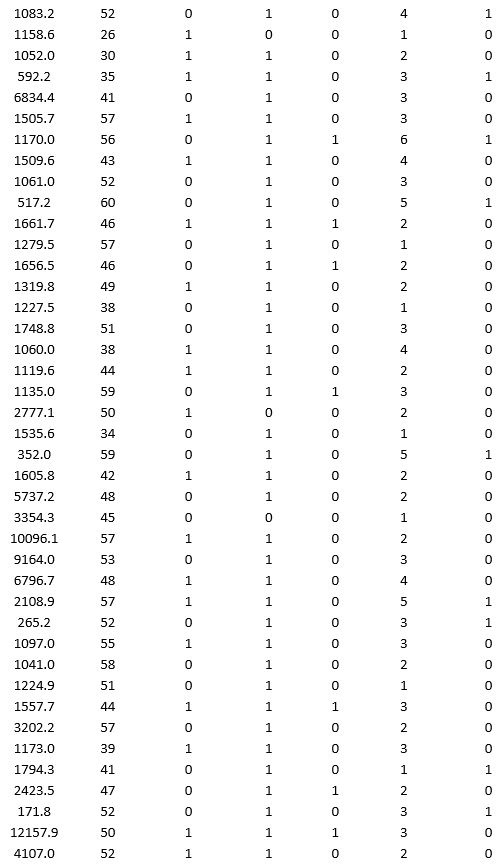
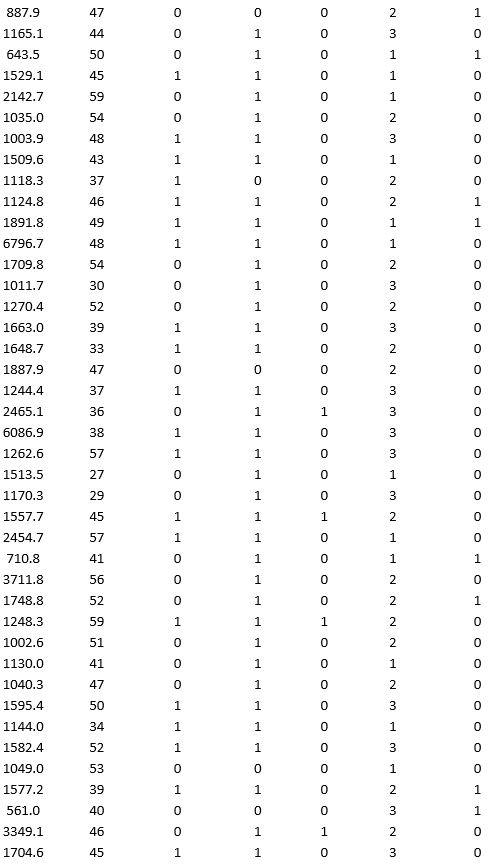
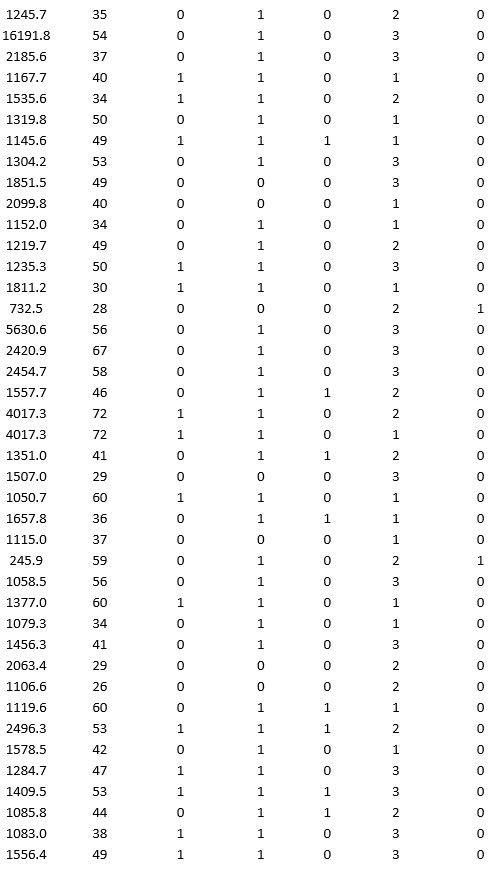
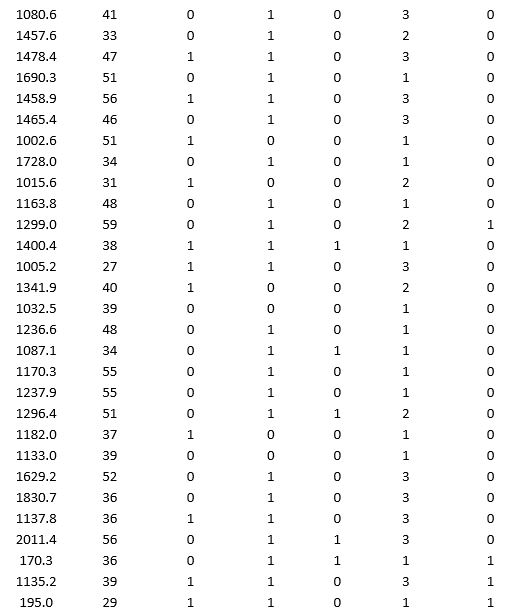
In XLMiner's Partition with Oversampling procedure, partition the data so there is 50 percent successes (Loan default) in the training set and 40 percent of the validation data are taken away as test data. Construct a logistic regression model using Loan default as the output variable and all the other variables as input variables. Perform an exhaustive-search best subset selection with the number of best subsets equal to 2. Generate lift charts for both the validation data and test data.
a. From the generated set of logistic regression models, select one that is a good fit. Express the model as a mathematical equation relating the output variable to the input variables. Do the relationships suggested by the model make sense? Try to explain them.
b. Using the default cutoff value of 0.5 for your logistic regression model, what is the overall error rate on the test data?
c. Examine the decile-wise lift chart for your model on the test data. What is the first decile lift? Interpret this value.
Correct Answer:

Verified
a. Using Mallow's Cp statistic to guide ...View Answer
Unlock this answer now
Get Access to more Verified Answers free of charge
Correct Answer:
Verified
View Answer
Unlock this answer now
Get Access to more Verified Answers free of charge
Q1: A retailer is interested in analyzing the
Q3: _ is a category of data-mining techniques
Q4: _ is a measure of calculating dissimilarity
Q4: A _ classifies a categorical outcome variable
Q5: The simplest measure of similarity between observations
Q7: The process of reducing the number of
Q9: The estimation of the value for a
Q10: Which of the following is true of
Q11: A research team wanted to assess the
Q35: In the k-nearest neighbors method, when the