Exam 7: AWS Certified Machine Learning - Specialty (MLS-C01)
Exam 1: AWS Certified Advanced Networking - Specialty (ANS-C00)397 Questions
Exam 2: AWS Certified Alexa Skill Builder - Specialty68 Questions
Exam 3: AWS Certified Cloud Practitioner (CLF-C01)803 Questions
Exam 4: AWS Certified Data Analytics - Specialty (DAS-C01)135 Questions
Exam 5: AWS Certified Database - Specialty156 Questions
Exam 6: AWS Certified Developer Associate (DVA-C01)470 Questions
Exam 7: AWS Certified Machine Learning - Specialty (MLS-C01)159 Questions
Exam 8: AWS Certified Security - Specialty (SCS-C01)295 Questions
Exam 9: AWS Certified Solutions Architect - Associate SAA-C02596 Questions
Exam 10: AWS Certified Solutions Architect - Professional (SAP-C01)871 Questions
Exam 11: AWS Certified SysOps Administrator - Associate (SOA-C02)54 Questions
Exam 12: AWS DevOps Engineer - Professional (DOP-C01)610 Questions
Exam 13: AWS Certified SysOps Administrator (SOA-C01)976 Questions
Select questions type
A library is developing an automatic book-borrowing system that uses Amazon Rekognition. Images of library members' faces are stored in an Amazon S3 bucket. When members borrow books, the Amazon Rekognition CompareFaces API operation compares real faces against the stored faces in Amazon S3. The library needs to improve security by making sure that images are encrypted at rest. Also, when the images are used with Amazon Rekognition. they need to be encrypted in transit. The library also must ensure that the images are not used to improve Amazon Rekognition as a service. How should a machine learning specialist architect the solution to satisfy these requirements?
(Multiple Choice)
4.8/5  (28)
(28)
A Machine Learning Specialist receives customer data for an online shopping website. The data includes demographics, past visits, and locality information. The Specialist must develop a machine learning approach to identify the customer shopping patterns, preferences, and trends to enhance the website-for better service and smart recommendations. Which solution should the Specialist recommend?
(Multiple Choice)
4.8/5 (36)
A Machine Learning Specialist is deciding between building a naive Bayesian model or a full Bayesian network for a classification problem. The Specialist computes the Pearson correlation coefficients between each feature and finds that their absolute values range between 0.1 to 0.95. Which model describes the underlying data in this situation?
(Multiple Choice)
4.8/5 (31)
A Machine Learning Specialist kicks off a hyperparameter tuning job for a tree-based ensemble model using Amazon SageMaker with Area Under the ROC Curve (AUC) as the objective metric. This workflow will eventually be deployed in a pipeline that retrains and tunes hyperparameters each night to model click-through on data that goes stale every 24 hours. With the goal of decreasing the amount of time it takes to train these models, and ultimately to decrease costs, the Specialist wants to reconfigure the input hyperparameter range(s). Which visualization will accomplish this?
(Multiple Choice)
4.7/5 (32)
A Machine Learning Specialist is building a prediction model for a large number of features using linear models, such as linear regression and logistic regression. During exploratory data analysis, the Specialist observes that many features are highly correlated with each other. This may make the model unstable. What should be done to reduce the impact of having such a large number of features?
(Multiple Choice)
4.7/5 (33)
A company is running a machine learning prediction service that generates 100 TB of predictions every day. A Machine Learning Specialist must generate a visualization of the daily precision-recall curve from the predictions, and forward a read-only version to the Business team. Which solution requires the LEAST coding effort?
(Multiple Choice)
4.8/5 (29)
This graph shows the training and validation loss against the epochs for a neural network. The network being trained is as follows: Two dense layers, one output neuron 100 neurons in each layer 100 epochs Random initialization of weights 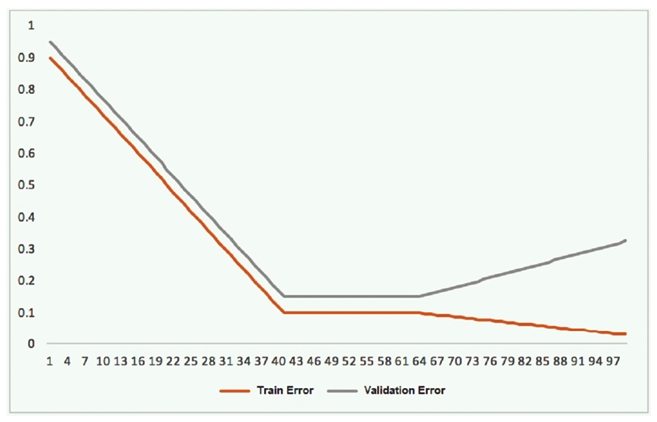 Which technique can be used to improve model performance in terms of accuracy in the validation set?
Which technique can be used to improve model performance in terms of accuracy in the validation set?
(Multiple Choice)
4.8/5 (38)
A data scientist wants to use Amazon Forecast to build a forecasting model for inventory demand for a retail company. The company has provided a dataset of historic inventory demand for its products as a .csv file stored in an Amazon S3 bucket. The table below shows a sample of the dataset.  How should the data scientist transform the data?
How should the data scientist transform the data?
(Multiple Choice)
4.8/5 (29)
A data scientist is developing a pipeline to ingest streaming web traffic data. The data scientist needs to implement a process to identify unusual web traffic patterns as part of the pipeline. The patterns will be used downstream for alerting and incident response. The data scientist has access to unlabeled historic data to use, if needed. The solution needs to do the following: Calculate an anomaly score for each web traffic entry. Adapt unusual event identification to changing web patterns over time. Which approach should the data scientist implement to meet these requirements?
(Multiple Choice)
4.8/5 (38)
A Machine Learning Specialist prepared the following graph displaying the results of k-means for k = [1..10]: ![A Machine Learning Specialist prepared the following graph displaying the results of k-means for k = [1..10]: Considering the graph, what is a reasonable selection for the optimal choice of k?](https://storage.examlex.com/C1091/11ec5816_da5a_eec3_92e9_37923714a808_C1091_00.jpg) Considering the graph, what is a reasonable selection for the optimal choice of k?
Considering the graph, what is a reasonable selection for the optimal choice of k?
(Multiple Choice)
4.7/5 (30)
An e commerce company wants to launch a new cloud-based product recommendation feature for its web application. Due to data localization regulations, any sensitive data must not leave its on-premises data center, and the product recommendation model must be trained and tested using nonsensitive data only. Data transfer to the cloud must use IPsec. The web application is hosted on premises with a PostgreSQL database that contains all the data. The company wants the data to be uploaded securely to Amazon S3 each day for model retraining. How should a machine learning specialist meet these requirements?
(Multiple Choice)
4.9/5 (34)
A trucking company is collecting live image data from its fleet of trucks across the globe. The data is growing rapidly and approximately 100 GB of new data is generated every day. The company wants to explore machine learning uses cases while ensuring the data is only accessible to specific IAM users. Which storage option provides the most processing flexibility and will allow access control with IAM?
(Multiple Choice)
4.9/5 (40)
A manufacturer is operating a large number of factories with a complex supply chain relationship where unexpected downtime of a machine can cause production to stop at several factories. A data scientist wants to analyze sensor data from the factories to identify equipment in need of preemptive maintenance and then dispatch a service team to prevent unplanned downtime. The sensor readings from a single machine can include up to 200 data points including temperatures, voltages, vibrations, RPMs, and pressure readings. To collect this sensor data, the manufacturer deployed Wi-Fi and LANs across the factories. Even though many factory locations do not have reliable or high-speed internet connectivity, the manufacturer would like to maintain near-real-time inference capabilities. Which deployment architecture for the model will address these business requirements?
(Multiple Choice)
4.8/5 (25)
A company is running a machine learning prediction service that generates 100 TB of predictions every day. A Machine Learning Specialist must generate a visualization of the daily precision-recall curve from the predictions, and forward a read-only version to the Business team. Which solution requires the LEAST coding effort?
(Multiple Choice)
4.8/5 (28)
A company that promotes healthy sleep patterns by providing cloud-connected devices currently hosts a sleep tracking application on AWS. The application collects device usage information from device users. The company's Data Science team is building a machine learning model to predict if and when a user will stop utilizing the company's devices. Predictions from this model are used by a downstream application that determines the best approach for contacting users. The Data Science team is building multiple versions of the machine learning model to evaluate each version against the company's business goals. To measure long-term effectiveness, the team wants to run multiple versions of the model in parallel for long periods of time, with the ability to control the portion of inferences served by the models. Which solution satisfies these requirements with MINIMAL effort?
(Multiple Choice)
4.7/5 (42)
A credit card company wants to build a credit scoring model to help predict whether a new credit card applicant will default on a credit card payment. The company has collected data from a large number of sources with thousands of raw attributes. Early experiments to train a classification model revealed that many attributes are highly correlated, the large number of features slows down the training speed significantly, and that there are some overfitting issues. The Data Scientist on this project would like to speed up the model training time without losing a lot of information from the original dataset. Which feature engineering technique should the Data Scientist use to meet the objectives?
(Multiple Choice)
4.8/5 (30)
A machine learning specialist works for a fruit processing company and needs to build a system that categorizes apples into three types. The specialist has collected a dataset that contains 150 images for each type of apple and applied transfer learning on a neural network that was pretrained on ImageNet with this dataset. The company requires at least 85% accuracy to make use of the model. After an exhaustive grid search, the optimal hyperparameters produced the following: 68% accuracy on the training set 67% accuracy on the validation set What can the machine learning specialist do to improve the system's accuracy?
(Multiple Choice)
4.9/5 (30)
A financial services company wants to adopt Amazon SageMaker as its default data science environment. The company's data scientists run machine learning (ML) models on confidential financial data. The company is worried about data egress and wants an ML engineer to secure the environment. Which mechanisms can the ML engineer use to control data egress from SageMaker? (Choose three.)
(Multiple Choice)
5.0/5 (42)
An online reseller has a large, multi-column dataset with one column missing 30% of its data. A Machine Learning Specialist believes that certain columns in the dataset could be used to reconstruct the missing data. Which reconstruction approach should the Specialist use to preserve the integrity of the dataset?
(Multiple Choice)
4.8/5 (42)
A company is converting a large number of unstructured paper receipts into images. The company wants to create a model based on natural language processing (NLP) to find relevant entities such as date, location, and notes, as well as some custom entities such as receipt numbers. The company is using optical character recognition (OCR) to extract text for data labeling. However, documents are in different structures and formats, and the company is facing challenges with setting up the manual workflows for each document type. Additionally, the company trained a named entity recognition (NER) model for custom entity detection using a small sample size. This model has a very low confidence score and will require retraining with a large dataset. Which solution for text extraction and entity detection will require the LEAST amount of effort?
(Multiple Choice)
4.8/5 (39)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)