Exam 7: AWS Certified Machine Learning - Specialty (MLS-C01)
Exam 1: AWS Certified Advanced Networking - Specialty (ANS-C00)397 Questions
Exam 2: AWS Certified Alexa Skill Builder - Specialty68 Questions
Exam 3: AWS Certified Cloud Practitioner (CLF-C01)803 Questions
Exam 4: AWS Certified Data Analytics - Specialty (DAS-C01)135 Questions
Exam 5: AWS Certified Database - Specialty156 Questions
Exam 6: AWS Certified Developer Associate (DVA-C01)470 Questions
Exam 7: AWS Certified Machine Learning - Specialty (MLS-C01)159 Questions
Exam 8: AWS Certified Security - Specialty (SCS-C01)295 Questions
Exam 9: AWS Certified Solutions Architect - Associate SAA-C02596 Questions
Exam 10: AWS Certified Solutions Architect - Professional (SAP-C01)871 Questions
Exam 11: AWS Certified SysOps Administrator - Associate (SOA-C02)54 Questions
Exam 12: AWS DevOps Engineer - Professional (DOP-C01)610 Questions
Exam 13: AWS Certified SysOps Administrator (SOA-C01)976 Questions
Select questions type
A monitoring service generates 1 TB of scale metrics record data every minute. A Research team performs queries on this data using Amazon Athena. The queries run slowly due to the large volume of data, and the team requires better performance. How should the records be stored in Amazon S3 to improve query performance?
(Multiple Choice)
4.8/5  (35)
(35)
A company is observing low accuracy while training on the default built-in image classification algorithm in Amazon SageMaker. The Data Science team wants to use an Inception neural network architecture instead of a ResNet architecture. Which of the following will accomplish this? (Choose two.)
(Multiple Choice)
4.8/5 (38)
A large consumer goods manufacturer has the following products on sale: • 34 different toothpaste variants • 48 different toothbrush variants • 43 different mouthwash variants The entire sales history of all these products is available in Amazon S3. Currently, the company is using custom-built autoregressive integrated moving average (ARIMA) models to forecast demand for these products. The company wants to predict the demand for a new product that will soon be launched. Which solution should a Machine Learning Specialist apply?
(Multiple Choice)
4.8/5 (43)
A manufacturing company has a large set of labeled historical sales data. The manufacturer would like to predict how many units of a particular part should be produced each quarter. Which machine learning approach should be used to solve this problem?
(Multiple Choice)
4.8/5 (30)
A data scientist uses an Amazon SageMaker notebook instance to conduct data exploration and analysis. This requires certain Python packages that are not natively available on Amazon SageMaker to be installed on the notebook instance. How can a machine learning specialist ensure that required packages are automatically available on the notebook instance for the data scientist to use?
(Multiple Choice)
5.0/5 (40)
A Machine Learning Specialist is creating a new natural language processing application that processes a dataset comprised of 1 million sentences. The aim is to then run Word2Vec to generate embeddings of the sentences and enable different types of predictions. Here is an example from the dataset: "The quck BROWN FOX jumps over the lazy dog." Which of the following are the operations the Specialist needs to perform to correctly sanitize and prepare the data in a repeatable manner? (Choose three.)
(Multiple Choice)
4.9/5 (27)
A company is using Amazon Textract to extract textual data from thousands of scanned text-heavy legal documents daily. The company uses this information to process loan applications automatically. Some of the documents fail business validation and are returned to human reviewers, who investigate the errors. This activity increases the time to process the loan applications. What should the company do to reduce the processing time of loan applications?
(Multiple Choice)
4.9/5 (37)
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a Machine Learning Specialist would like to build a binary classifier based on two features: age of account and transaction month. The class distribution for these features is illustrated in the figure provided. 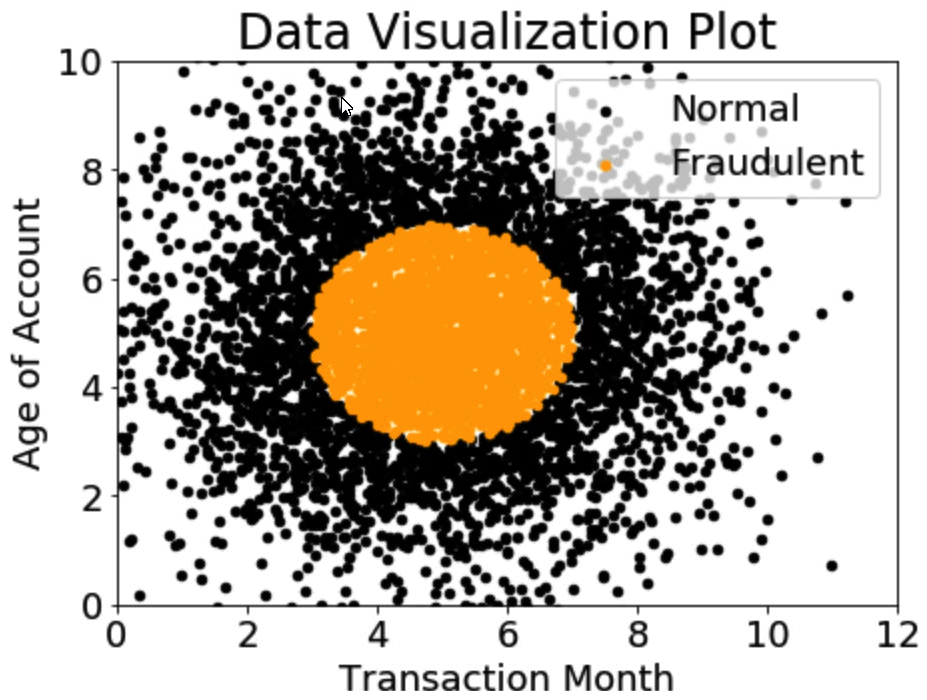 Based on this information, which model would have the HIGHEST accuracy?
Based on this information, which model would have the HIGHEST accuracy?
(Multiple Choice)
4.9/5 (51)
A Machine Learning Specialist is working with a large cybersecurity company that manages security events in real time for companies around the world. The cybersecurity company wants to design a solution that will allow it to use machine learning to score malicious events as anomalies on the data as it is being ingested. The company also wants be able to save the results in its data lake for later processing and analysis. What is the MOST efficient way to accomplish these tasks?
(Multiple Choice)
4.8/5 (43)
A manufacturing company uses machine learning (ML) models to detect quality issues. The models use images that are taken of the company's product at the end of each production step. The company has thousands of machines at the production site that generate one image per second on average. The company ran a successful pilot with a single manufacturing machine. For the pilot, ML specialists used an industrial PC that ran AWS IoT Greengrass with a long-running AWS Lambda function that uploaded the images to Amazon S3. The uploaded images invoked a Lambda function that was written in Python to perform inference by using an Amazon SageMaker endpoint that ran a custom model. The inference results were forwarded back to a web service that was hosted at the production site to prevent faulty products from being shipped. The company scaled the solution out to all manufacturing machines by installing similarly configured industrial PCs on each production machine. However, latency for predictions increased beyond acceptable limits. Analysis shows that the internet connection is at its capacity limit. How can the company resolve this issue MOST cost-effectively?
(Multiple Choice)
4.8/5 (34)
An interactive online dictionary wants to add a widget that displays words used in similar contexts. A Machine Learning Specialist is asked to provide word features for the downstream nearest neighbor model powering the widget. What should the Specialist do to meet these requirements?
(Multiple Choice)
4.8/5 (38)
A Data Scientist is developing a machine learning model to classify whether a financial transaction is fraudulent. The labeled data available for training consists of 100,000 non-fraudulent observations and 1,000 fraudulent observations. The Data Scientist applies the XGBoost algorithm to the data, resulting in the following confusion matrix when the trained model is applied to a previously unseen validation dataset. The accuracy of the model is 99.1%, but the Data Scientist needs to reduce the number of false negatives. 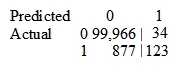 Which combination of steps should the Data Scientist take to reduce the number of false negative predictions by the model? (Choose two.)
Which combination of steps should the Data Scientist take to reduce the number of false negative predictions by the model? (Choose two.)
(Multiple Choice)
4.8/5 (42)
Machine Learning Specialist is training a model to identify the make and model of vehicles in images. The Specialist wants to use transfer learning and an existing model trained on images of general objects. The Specialist collated a large custom dataset of pictures containing different vehicle makes and models. What should the Specialist do to initialize the model to re-train it with the custom data?
(Multiple Choice)
4.8/5 (44)
A logistics company needs a forecast model to predict next month's inventory requirements for a single item in 10 warehouses. A machine learning specialist uses Amazon Forecast to develop a forecast model from 3 years of monthly data. There is no missing data. The specialist selects the DeepAR+ algorithm to train a predictor. The predictor means absolute percentage error (MAPE) is much larger than the MAPE produced by the current human forecasters. Which changes to the CreatePredictor API call could improve the MAPE? (Choose two.)
(Multiple Choice)
4.8/5 (36)
A Data Scientist is developing a machine learning model to predict future patient outcomes based on information collected about each patient and their treatment plans. The model should output a continuous value as its prediction. The data available includes labeled outcomes for a set of 4,000 patients. The study was conducted on a group of individuals over the age of 65 who have a particular disease that is known to worsen with age. Initial models have performed poorly. While reviewing the underlying data, the Data Scientist notices that, out of 4,000 patient observations, there are 450 where the patient age has been input as 0. The other features for these observations appear normal compared to the rest of the sample population How should the Data Scientist correct this issue?
(Multiple Choice)
4.8/5 (40)
A Machine Learning team runs its own training algorithm on Amazon SageMaker. The training algorithm requires external assets. The team needs to submit both its own algorithm code and algorithm-specific parameters to Amazon SageMaker. What combination of services should the team use to build a custom algorithm in Amazon SageMaker? (Choose two.)
(Multiple Choice)
4.9/5 (34)
A monitoring service generates 1 TB of scale metrics record data every minute. A Research team performs queries on this data using Amazon Athena. The queries run slowly due to the large volume of data, and the team requires better performance. How should the records be stored in Amazon S3 to improve query performance?
(Multiple Choice)
4.8/5 (41)
Machine Learning Specialist is building a model to predict future employment rates based on a wide range of economic factors. While exploring the data, the Specialist notices that the magnitude of the input features vary greatly. The Specialist does not want variables with a larger magnitude to dominate the model. What should the Specialist do to prepare the data for model training?
(Multiple Choice)
4.8/5 (33)
A Machine Learning Specialist is assigned a TensorFlow project using Amazon SageMaker for training, and needs to continue working for an extended period with no Wi-Fi access. Which approach should the Specialist use to continue working?
(Multiple Choice)
4.7/5 (29)
A Data Scientist is training a multilayer perception (MLP) on a dataset with multiple classes. The target class of interest is unique compared to the other classes within the dataset, but it does not achieve and acceptable recall metric. The Data Scientist has already tried varying the number and size of the MLP's hidden layers, which has not significantly improved the results. A solution to improve recall must be implemented as quickly as possible. Which techniques should be used to meet these requirements?
(Multiple Choice)
4.9/5 (37)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)