Exam 18: GIS Models and Modeling
Geographically weighted regression builds a regression model for each observation in the data set.
True
Explain the difference between "crisp threshold values" and "fuzzy sets" in multicriteria evaluation.
In multicriteria evaluation, "crisp threshold values" and "fuzzy sets" are two different approaches used to handle uncertainty and vagueness in decision-making processes.
Crisp threshold values are used in traditional decision-making methods where a clear and precise cutoff point is defined to separate different categories or classes. For example, in a binary classification problem, a crisp threshold value might be set to distinguish between "acceptable" and "unacceptable" options based on a specific criterion. This approach assumes that the data is precise and that there is no ambiguity in the decision-making process.
On the other hand, fuzzy sets allow for a more flexible and nuanced representation of uncertainty. Instead of using strict cutoff points, fuzzy sets allow for the gradual transition between different categories. This means that an option can belong to multiple categories to varying degrees, reflecting the inherent vagueness in real-world decision-making. Fuzzy sets are particularly useful when dealing with subjective or imprecise data, as they can capture the uncertainty and ambiguity present in the decision-making process.
In summary, the main difference between crisp threshold values and fuzzy sets lies in their treatment of uncertainty. Crisp threshold values rely on clear cutoff points and precise categorization, while fuzzy sets allow for a more flexible and nuanced representation of uncertainty, making them more suitable for handling complex and ambiguous decision-making scenarios in multicriteria evaluation.
How does an index model differ from a binary model?
An index model and a binary model are two different types of models used in various fields such as finance, statistics, and computer science. They serve different purposes and are based on different principles. Here's how they differ:
Index Model:
1. An index model is used to describe the relationship between the return on a specific asset and the return on a market index. It is commonly used in finance, particularly in the Capital Asset Pricing Model (CAPM).
2. The index model assumes that the return on an asset is partly due to the market return and partly due to factors unique to the asset itself.
3. The model typically includes a systematic risk component represented by the market index and an unsystematic risk component that is asset-specific.
4. The index model can be represented by a linear equation: Ri = αi + βiRm + εi, where Ri is the return on asset i, αi is the asset's expected return independent of the market, βi is the asset's sensitivity to the market index (Rm), and εi is the random error term.
5. The index model is continuous in nature, meaning that the returns can take on any value within a range.
Binary Model:
1. A binary model, on the other hand, is used to predict outcomes that have two possible states, often referred to as "success" and "failure" or "1" and "0". It is widely used in fields like statistics, machine learning, and decision-making.
2. The binary model is used for classification purposes, where the goal is to categorize observations into one of two distinct groups.
3. This model does not typically involve a market index or any continuous variable as a predictor. Instead, it uses one or more independent variables to predict a binary outcome.
4. A common example of a binary model is logistic regression, where the probability of the outcome is modeled as a logistic function of the independent variables: P(Y=1) = 1 / (1 + e^-(β0 + β1X1 + ... + βnXn)).
5. The binary model is discrete in nature, as it deals with categorical outcomes rather than a continuous range of values.
In summary, an index model is used to explain the relationship between an asset's return and the market return, incorporating both systematic and unsystematic risk factors. It deals with continuous data and is often used in the context of financial markets. A binary model, on the other hand, is used for classification tasks with two possible outcomes and is applicable in various fields where such predictions are necessary. It deals with categorical, discrete data.
Many index models use the weighted linear combination method to calculate the index value. Explain the steps one follows in using the weighted linear combination method.
An environmental model such as a soil erosion model must be capable of dealing with the interaction of many variables including physical and cultural variables.
Which of the following analyses commonly uses index models?
To build an index model, one must assign a(n) ____ to each variable or factor under consideration:
In many instances, one can build a GIS model that is either vector-based or raster-based. What general guidelines should one use in deciding which type of model to build?
Which method is used by RUSLE to compute the average soil loss from six factors?
A common approach to building a vector-based binary model is to
A number of alternatives to the weighted linear combination method have been proposed in the literature. Describe one such alternative.
It is recommended that data sets used for validating a model are different from those for developing the model.
You are asked to develop a vector-based index model. The model computes the index value using elevation and slope:
Index value = 2 * elevation + slope
The scoring (data standardization) systems for elevation and slope are as follows:
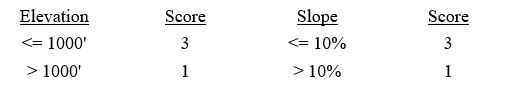 You already have the elevation and slope layers. Describe the procedure you will follow to complete the task.
You already have the elevation and slope layers. Describe the procedure you will follow to complete the task.
A model that offers prediction of what the conditions of geospatial data could be or should be is called a
How does a deterministic model differ from a stochastic model?
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)