Exam 15: Multiple Regression Model Building
Exam 1: Introduction and Data Collection137 Questions
Exam 2: Presenting Data in Tables and Charts181 Questions
Exam 3: Numerical Descriptive Measures138 Questions
Exam 4: Basic Probability152 Questions
Exam 5: Some Important Discrete Probability Distributions174 Questions
Exam 6: The Normal Distribution and Other Continuous Distributions180 Questions
Exam 7: Sampling Distributions and Sampling180 Questions
Exam 8: Confidence Interval Estimation185 Questions
Exam 9: Fundamentals of Hypothesis Testing: One-Sample Tests180 Questions
Exam 10: Two-Sample Tests184 Questions
Exam 11: Analysis of Variance179 Questions
Exam 12: Chi-Square Tests and Nonparametric Tests206 Questions
Exam 13: Simple Linear Regression196 Questions
Exam 14: Introduction to Multiple Regression258 Questions
Exam 15: Multiple Regression Model Building88 Questions
Exam 16: Time-Series Forecasting and Index Numbers193 Questions
Exam 17: Decision Making127 Questions
Exam 18: Statistical Applications in Quality Management113 Questions
Exam 19: Statistical Analysis Scenarios and Distributions82 Questions
Select questions type
TABLE 15- 8
The superintendent of a school district wanted to predict the percentage of students passing a sixth- grade proficiency test. She obtained the data on percentage of students passing the proficiency test (% Passing), daily average of the percentage of students attending class (% Attendance), average teacher salary in dollars (Salaries), and instructional spending per pupil in dollars (Spending) of 47 schools in the state.
Let Y = % Passing as the dependent variable, X1 = % Attendance, X2 = Salaries and X3 = Spending.
The coefficient of multiple determination (R 2 j) of each of the 3 predictors with all the other remaining predictors are,respectively, 0.0338, 0.4669, and 0.4743.
The output from the best- subset regressions is given below:
Adjusted Model Variables R Square R Square Std. Error 1 X1 3.05 2 0.6024 0.5936 10.5787 2 X1X2 3.66 3 0.6145 0.5970 10.5350 3 X1X2X3 4.00 4 0.6288 0.6029 10.4570 4 X1X3 2.00 3 0.6288 0.6119 10.3375 5 X2 67.35 2 0.0474 0.0262 16.3755 6 X2X3 64.30 3 0.0910 0.0497 16.1768 7 X3 62.33 2 0.0907 0.0705 15.9984
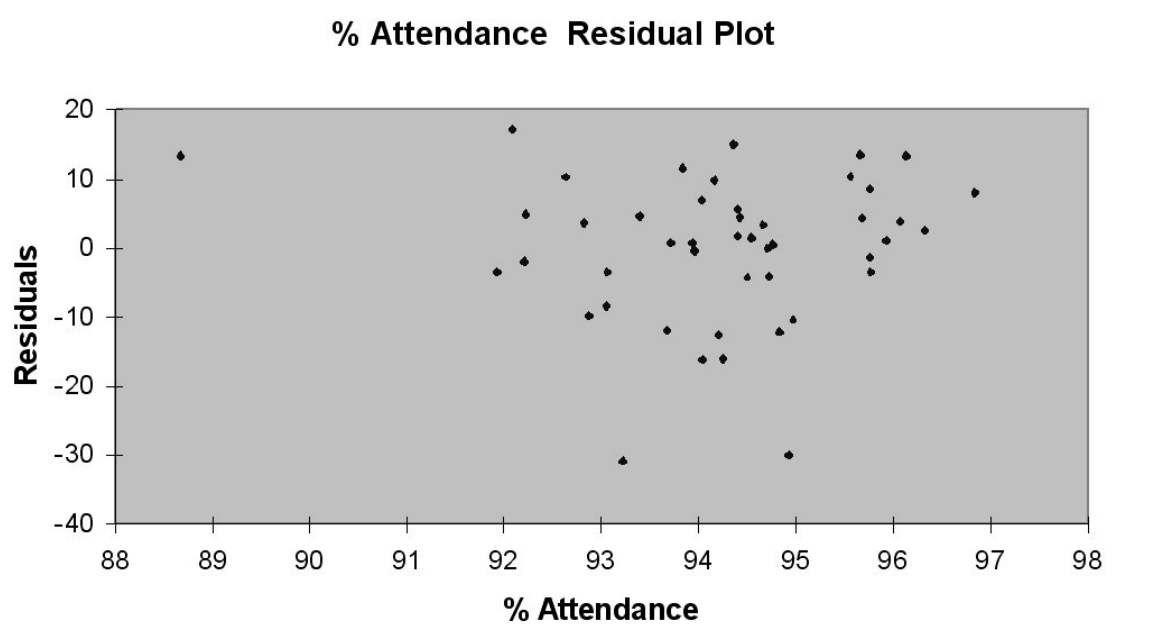
Following is the residual plot for % Attendance:
 Following is the output of several multiple regression models:
Coefficients Std Error Stat p-value Lower 95\% Upper 95\% Intercept -753.4225 101.1149 -7.4511 2.88-09 -957.3401 -549.5050 \% Attend 8.5014 1.0771 7.8929 6.73-10 6.3292 10.6735 Salary 6.85-07 0.0006 0.0011 0.9991 -0.0013 0.0013 Spending 0.0060 0.0046 1.2879 0.2047 -0.0034 0.0153
Coefficients Standard Error t Stat p -value Intercept -753.4086 99.1451 -7.5991 1.5291-09 \% Attendance 8.5014 1.0645 7.9862 4.223-10 Spending 0.0060 0.0034 1.7676 0.0840
d f SS MS F Significance F Regression 2 8162.9429 4081.4714 39.8708 1.3201-10 Residual 44 4504.1635 102.3674 Total 46 12667.1064
Coefficients Standard Error t Stat p -value Intercept 6672.8367 3267.7349 2.0420 0.0472 \% Attendance -150.5694 69.9519 -2.1525 0.0369 \% Attendance Squared 0.8532 0.3743 2.2792 0.0276
-Referring to Table 15-8, the "best" model using a 5% level of significance among those chosen by the Cp statistic is
Following is the output of several multiple regression models:
Coefficients Std Error Stat p-value Lower 95\% Upper 95\% Intercept -753.4225 101.1149 -7.4511 2.88-09 -957.3401 -549.5050 \% Attend 8.5014 1.0771 7.8929 6.73-10 6.3292 10.6735 Salary 6.85-07 0.0006 0.0011 0.9991 -0.0013 0.0013 Spending 0.0060 0.0046 1.2879 0.2047 -0.0034 0.0153
Coefficients Standard Error t Stat p -value Intercept -753.4086 99.1451 -7.5991 1.5291-09 \% Attendance 8.5014 1.0645 7.9862 4.223-10 Spending 0.0060 0.0034 1.7676 0.0840
d f SS MS F Significance F Regression 2 8162.9429 4081.4714 39.8708 1.3201-10 Residual 44 4504.1635 102.3674 Total 46 12667.1064
Coefficients Standard Error t Stat p -value Intercept 6672.8367 3267.7349 2.0420 0.0472 \% Attendance -150.5694 69.9519 -2.1525 0.0369 \% Attendance Squared 0.8532 0.3743 2.2792 0.0276
-Referring to Table 15-8, the "best" model using a 5% level of significance among those chosen by the Cp statistic is
(Multiple Choice)
4.7/5  (33)
(33)
TABLE 15-3
A certain type of rare gem serves as a status symbol for many of its owners. In theory, for low prices, the demand increases and it decreases as the price of the gem increases. However, experts hypothesize that when the gem is valued at very high prices, the demand increases with price due to the status owners believe they gain in obtaining the gem. Thus, the model proposed to best explain the demand for the gem by its price is the quadratic model:
where Y = demand (in thousands) and X = retail price per carat.
This model was fit to data collected for a sample of 12 rare gems of this type. A portion of the computer analysis obtained from Microsoft Excel is shown below:
SUMMARY OUTPUT
Regression Statistics Multiple R 0.994 R Square 0.988 Standard Error 12.42 Observations 12
df SS MS F Signifcance F Regression 2 115145 57573 373 0.0001 Residual 9 1388 154 Total 11 116533
Coeff Std Error t Stat p-value Intercept 286.42 9.66 29.64 0.0001 Price -0.31 0.06 -5.14 0.0006 Frice Sq 0.000067 0.00007 0.95 0.3647
-Referring to Table 15-3, what is the p-value associated with the test statistic for testing whether there is an upward curvature in the response curve relating the demand (Y) and the price (X)?
(Multiple Choice)
4.8/5 (34)
Which of the following is used to determine observations that have influential effect on the fitted model?
(Multiple Choice)
4.8/5 (37)
TABLE 15-1
To explain personal consumption (CONS) measured in dollars, data is collected for
A regression analysis was performed with CONS as the dependent variable and ln(CRDTLIM), ln(APR), ln(ADVT), and SEX as the independent variables. The estimated model was
y^ = 2.28 - 0.29 ln(CRDTLIM) + 5.77 ln(APR) + 2.35 ln(ADVT) + 0.39 SEX
-Referring to Table 15-1, what is the correct interpretation for the estimated coefficient for ADVT?
(Multiple Choice)
4.9/5 (39)
TABLE 15-7
A chemist employed by a pharmaceutical firm has developed a muscle relaxant. She took a sample of 14 people suffering from extreme muscle constriction. She gave each a vial containing a dose (X) of the drug and recorded the time to relief (Y) measured in seconds for each. She fit a "centered" curvilinear model to this data. The results obtained by Microsoft Excel follow, where the dose (X) given has been "centered."
SUMMARY OUTPUT
Regression Statistics Multiple R 0.747 RSquare 0.558 Adjusted R Square 0.478 Standard Error 863.1 Observations 14 ANOVA df SS MS F Significance F Regression 2 10344797 5172399 6.94 0.0110 Residual 11 8193929 744903 Total 13 18538726 Coeff Std Error t Stut p -value Intercept 1283.0 352.0 3.65 0.0040 CenDose 25.228 8.631 2.92 0.0140 CenDoseSq 0.8604 0.3722 2.31 0.0410
-Referring to Table 15-7, suppose the chemist decides to use a t test to determine if there is a significant difference between a linear model and a curvilinear model that includes a linear term. If she used a level of significance of 0.02, she would decide that the linear model is sufficient.
(True/False)
4.8/5 (26)
Which of the following will not change a nonlinear model into a linear model?
(Multiple Choice)
4.7/5 (34)
The stepwise regression approach takes into consideration all possible models.
(True/False)
4.9/5 (32)
TABLE 15- 8
The superintendent of a school district wanted to predict the percentage of students passing a sixth- grade proficiency test. She obtained the data on percentage of students passing the proficiency test (% Passing), daily average of the percentage of students attending class (% Attendance), average teacher salary in dollars (Salaries), and instructional spending per pupil in dollars (Spending) of 47 schools in the state.
Let Y = % Passing as the dependent variable, X1 = % Attendance, X2 = Salaries and X3 = Spending.
The coefficient of multiple determination (R 2 j) of each of the 3 predictors with all the other remaining predictors are,
respectively, 0.0338, 0.4669, and 0.4743.
The output from the best- subset regressions is given below:
Adjusted
Following is the residual plot for % Attendance:
Adjusted Model Variables R Square R Square Std. Error 1 X1 3.05 2 0.6024 0.5936 10.5787 2 X1X2 3.66 3 0.6145 0.5970 10.5350 3 X1X2X3 4.00 4 0.6288 0.6029 10.4570 4 X1X3 2.00 3 0.6288 0.6119 10.3375 5 X2 67.35 2 0.0474 0.0262 16.3755 6 X2X3 64.30 3 0.0910 0.0497 16.1768 7 X3 62.33 2 0.0907 0.0705 15.9984
Following is the residual plot for % Attendance:
Following is the output of several multiple regression models:
Coefficients Std Error Stat p-value Lower 95\% Upper 95\% Intercept -753.4225 101.1149 -7.4511 2.88-09 -957.3401 -549.5050 \% Attend 8.5014 1.0771 7.8929 6.73-10 6.3292 10.6735 Salary 6.85-07 0.0006 0.0011 0.9991 -0.0013 0.0013 Spending 0.0060 0.0046 1.2879 0.2047 -0.0034 0.0153
Coefficients Standard Error t Stat p -value Intercept -753.4086 99.1451 -7.5991 1.5291-09 \% Attendance 8.5014 1.0645 7.9862 4.223-10 Spending 0.0060 0.0034 1.7676 0.0840
d f SS MS F Significance F Regression 2 8162.9429 4081.4714 39.8708 1.3201-10 Residual 44 4504.1635 102.3674 Total 46 12667.1064
Coefficients Standard Error t Stat p -value Intercept 6672.8367 3267.7349 2.0420 0.0472 \% Attendance -150.5694 69.9519 -2.1525 0.0369 \% Attendance Squared 0.8532 0.3743 2.2792 0.0276
-Referring to Table 15-8, there is reason to suspect collinearity between some pairs of predictors.
(True/False)
4.9/5 (37)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)