Exam 7: Hypothesis Tests and Confidence Intervals in Multiple Regression
Exam 1: Economic Questions and Data11 Questions
Exam 2: Review of Probability61 Questions
Exam 3: Review of Statistics56 Questions
Exam 4: Linear Regression With One Regressor54 Questions
Exam 5: Regression With a Single Regressor: Hypothesis Tests and Confidence Intervals53 Questions
Exam 6: Linear Regression With Multiple Regressors54 Questions
Exam 7: Hypothesis Tests and Confidence Intervals in Multiple Regression50 Questions
Exam 8: Nonlinear Regression Functions53 Questions
Exam 9: Assessing Studies Based on Multiple Regression55 Questions
Exam 10: Regression With Panel Data40 Questions
Exam 11: Regression With a Binary Dependent Variable40 Questions
Exam 12: Instrumental Variables Regression40 Questions
Exam 13: Experiments and Quasi-Experiments40 Questions
Exam 14: Introduction to Time Series Regression and Forecasting36 Questions
Exam 15: Estimation of Dynamic Causal Effects40 Questions
Exam 16: Additional Topics in Time Series Regression40 Questions
Exam 17: The Theory of Linear Regression With One Regressor39 Questions
Exam 18: The Theory of Multiple Regression38 Questions
Select questions type
A 95% confidence set for two or more coefficients is a set that contains
Free
(Multiple Choice)
5.0/5  (29)
(29)
Correct Answer: Verified
Verified
D
If the absolute value of your calculated t-statistic exceeds the critical value from the standard normal distribution you can
Free
(Multiple Choice)
4.8/5 (37)
Correct Answer:Verified
B
You have collected data from Major League Baseball (MLB)to find the determinants of
winning.You have a general idea that both good pitching and strong hitting are needed to do
well.However, you do not know how much each of these contributes separately.To
investigate this problem, you collect data for all MLB during 1999 season.Your strategy is to
first regress the winning percentage on pitching quality ("Team ERA"), second to regress the
same variable on some measure of hitting ("OPS - On-base Plus Slugging percentage"), and
third to regress the winning percentage on both.
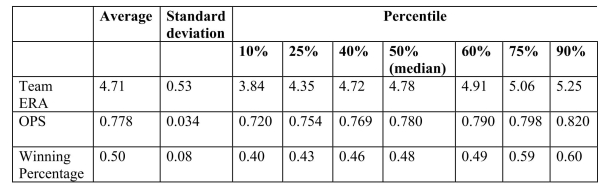 = 0.94-0.100\times teamera ,=0.49, SER =0.06. (0.08)(0.017) = -0.68+1.513\times ops ,=0.45, SER =0.06. (0.17)(0.221)
= -0.19-0.099\times teamera + (0.08)(0.008)(0.126) (a)Use the t-statistic to test for the statistical significance of the coefficient.
= 0.94-0.100\times teamera ,=0.49, SER =0.06. (0.08)(0.017) = -0.68+1.513\times ops ,=0.45, SER =0.06. (0.17)(0.221)
= -0.19-0.099\times teamera + (0.08)(0.008)(0.126) (a)Use the t-statistic to test for the statistical significance of the coefficient.
Free
(Essay)
4.9/5 (37)
Correct Answer:Verified
The t-statistic is only normally distributed in large samples.As a result,
inference is problematic here.
The Solow growth model suggests that countries with identical saving rates and population growth rates should converge to the same per capita income level. This result has been extended to include investment in human capital (education) as well as investment in physical capital. This hypothesis is referred to as the "conditional convergence hypothesis," since the convergence is dependent on countries obtaining the same values in the driving variables. To test the hypothesis, you collect data from the Penn World Tables on the average annual growth rate of GDP per worker for the 1960-1990 sample period, and regress it on the (i) initial starting level of GDP per worker relative to the United States in 1960 (RelProd ), (ii) average population growth rate of the country , (iii) average investment share of GDP from 1960 to - remember investment equals savings), and (iv) educational attainment in years for . The results for close to 100 countries is as follows (numbers in parentheses are for heteroskedasticity-robust standard errors): =0.004-0.172\timesn+0.133\times+0.002\times Educ -0.044\times (0.007)(0.209)(0.015)(0.001)(0.008) =0.537,SER=0.011 (a)Is the coefficient on this variable significantly different from zero at the 5% level? At the
1% level?
(Essay)
4.8/5 (45)
If the estimates of the coefficients of interest change substantially across specifications,
(Multiple Choice)
4.9/5 (39)
The -statistic with restrictions when testing for the restrictions and is given by the following formula:
Discuss how this formula can be understood intuitively.
(Essay)
4.8/5 (40)
When your multiple regression function includes a single omitted variable regressor, then
(Multiple Choice)
4.9/5 (40)
All of the following are true, with the exception of one condition: a. a high or does not mean that the regressors are a true cause of the dependent variable.
b. a high or does not mean that there is no omitted variable bias.
c. a high or always means that an added variable is statistically significant.
d. a high or does not necessarily mean that you have the most appropriate set of regressors.
(Short Answer)
4.8/5 (45)
When testing the null hypothesis that two regression slopes are zero simultaneously, then you cannot reject the null hypothesis at the 5% level, if the ellipse contains the point a. .
b. .
c. .
d. .
(Short Answer)
4.9/5 (40)
The formula for the standard error of the regression coefficient, when moving from one explanatory variable to two explanatory variables,
(Multiple Choice)
4.9/5 (40)
If you wanted to test, using a 5 % significance level, whether or not a specific slope coefficient is equal to one, then you should
(Multiple Choice)
4.7/5 (40)
The overall regression F-statistic tests the null hypothesis that
(Multiple Choice)
4.8/5 (32)
To test joint linear hypotheses in the multiple regression model, you need to a. compare the sums of squared residuals from the restricted and unrestricted model.
b. use the heteroskedasticity-robust -statistic.
c. use several -statistics and perform tests using the standard normal distribution.
d. compare the adjusted for the model which imposes the restrictions, and the unrestricted model.
(Short Answer)
5.0/5 (34)
Consider a situation where economic theory suggests that you impose certain restrictions
on your estimated multiple regression function.These may involve the equality of
parameters, such as the returns to education and on the job training in earnings functions,
or the sum of coefficients, such as constant returns to scale in a production function.To
test the validity of your restrictions, you have your statistical package calculate the
corresponding F-statistic.Find the critical value from the F-distribution at the 5% and 1%
level, and comment whether or not you will reject the null hypothesis in each of the
following cases.
(a)number of observations: 152; number of restrictions: 3; F-statistic: 3.21
(Essay)
4.8/5 (41)
Adding the Percent of English Speakers (PctEL)to the Student Teacher Ratio (STR)in
your textbook reduced the coefficient for STR from 2.28 to 1.10 with a standard error of
0.43.Construct a 90% and 99% confidence interval to test the hypothesis that the
coefficient of STR is 2.28.
(Essay)
4.7/5 (36)
Trying to remember the formula for the homoskedasticity-only F-statistic, you forgot
whether you subtract the restricted SSR from the unrestricted SSR or the other way
around.Your professor has provided you with a table containing critical values for the F
distribution.How can this be of help?
(Essay)
4.9/5 (32)
All of the following are correct formulae for the homoskedasticity-only F-statistic, with the exception of a. .
b. .
c. .
d. . 1
(Short Answer)
4.9/5 (42)
The OLS estimators of the coefficients in multiple regression will have omitted variable bias a. only if an omitted determinant of is a continuous variable.
b. if an omitted variable is correlated with at least one of the regressors, even though it is not a determinant of the dependent variable.
c. only if the omitted variable is not normally distributed.
d. if an omitted determinant of is correlated with at least one of the regressors.
(Short Answer)
4.8/5 (40)
In the multiple regression model, the t-statistic for testing that the slope is significantly different from zero is calculated a. by dividing the estimate by its standard error.
b. from the square root of the -statistic.
c. by multiplying the -value by .
d. using the adjusted and the confidence interval.
(Short Answer)
5.0/5 (38)
Consider the following Cobb-Douglas production function
(where Y is output, A is the level of technology, K is the capital stock, and L is the labor force), which has been linearized here (by using logarithms) to look as follows:
Assuming that the errors are heteroskedastic, you want to test for constant returns to scale. Using a t -statistic and "Approach #2," how would you proceed.
(Essay)
4.9/5 (34)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)