Exam 5: Regression With a Single Regressor: Hypothesis Tests and Confidence Intervals
Exam 1: Economic Questions and Data17 Questions
Exam 2: Review of Probability70 Questions
Exam 3: Review of Statistics65 Questions
Exam 4: Linear Regression With One Regressor65 Questions
Exam 5: Regression With a Single Regressor: Hypothesis Tests and Confidence Intervals59 Questions
Exam 6: Linear Regression With Multiple Regressors65 Questions
Exam 7: Hypothesis Tests and Confidence Intervals in Multiple Regression64 Questions
Exam 8: Nonlinear Regression Functions63 Questions
Exam 9: Assessing Studies Based on Multiple Regression65 Questions
Exam 10: Regression With Panel Data50 Questions
Exam 11: Regression With a Binary Dependent Variable50 Questions
Exam 12: Instrumental Variables Regression50 Questions
Exam 13: Experiments and Quasi-Experiments50 Questions
Exam 14: Introduction to Time Series Regression and Forecasting50 Questions
Exam 15: Estimation of Dynamic Causal Effects50 Questions
Exam 16: Additional Topics in Time Series Regression50 Questions
Exam 17: The Theory of Linear Regression With One Regressor49 Questions
Exam 18: The Theory of Multiple Regression50 Questions
Select questions type
The p-value for a one-sided left-tail test is given by
Free
(Multiple Choice)
5.0/5  (41)
(41)
Correct Answer: Verified
Verified
B
Finding a small value of the p-value (e.g. less than 5%)
Free
(Multiple Choice)
5.0/5 (38)
Correct Answer:Verified
C
Assume that the homoskedastic normal regression assumption hold. Using the Student t-distribution, find the critical value for the following situation:
(a)n = 28, 5% significance level, one-sided test.
(b)n = 40, 1% significance level, two-sided test.
(c)n = 10, 10% significance level, one-sided test.
(d)n = ∞, 5% significance level, two-sided test.
Free
(Essay)
4.8/5 (34)
Correct Answer:Verified
(a)1.71
(b)between 2.75 (30 degrees of freedom)and 2.66 (60 degrees of freedom)
(c)1.40
(d)1.96
With heteroskedastic errors, the weighted least squares estimator is BLUE. You should use OLS with heteroskedasticity-robust standard errors because
(Multiple Choice)
5.0/5 (33)
In a Monte Carlo study, econometricians generate multiple sample regression functions from a known population regression function. For example, the population regression function could be Yi = ?0 + ?1Xi = 100 - 0.5 Xi. The Xs could be generated randomly or, for simplicity, be nonrandom ("fixed over repeated samples"). If we had ten of these Xs, say, and generated twenty Ys, we would obviously always have all observations on a straight line, and the least squares formulae would always return values of 100 and 0.5 numerically. However, if we added an error term, where the errors would be drawn randomly from a normal distribution, say, then the OLS formulae would give us estimates that differed from the population regression function values. Assume you did just that and recorded the values for the slope and the intercept. Then you did the same experiment again (each one of these is called a "replication"). And so forth. After 1,000 replications, you plot the 1,000 intercepts and slopes, and list their summary statistics.
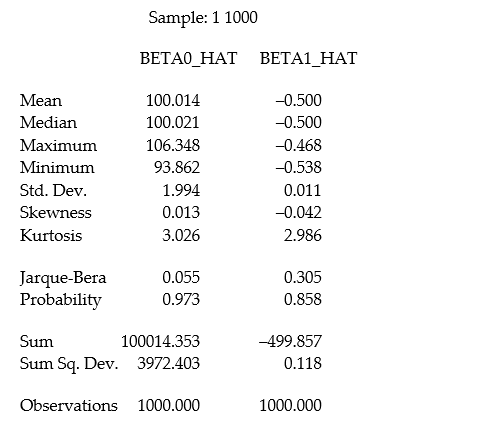 Here are the corresponding graphs:
Here are the corresponding graphs: 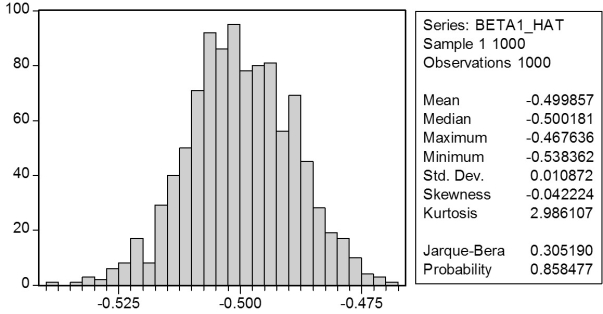
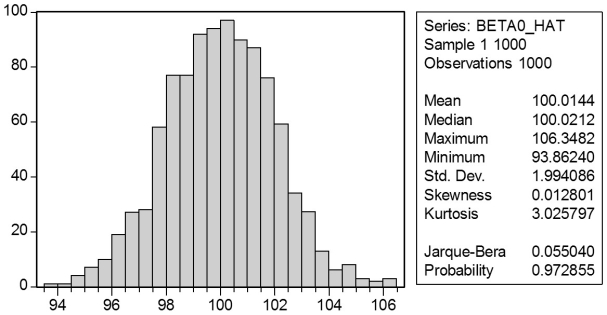 Using the means listed next to the graphs, you see that the averages are not exactly 100 and -0.5. However, they are "close." Test for the difference of these averages from the population values to be statistically significant.
Using the means listed next to the graphs, you see that the averages are not exactly 100 and -0.5. However, they are "close." Test for the difference of these averages from the population values to be statistically significant.
(Essay)
4.9/5 (35)
Carefully discuss the advantages of using heteroskedasticity-robust standard errors over standard errors calculated under the assumption of homoskedasticity. Give at least five examples where it is very plausible to assume that the errors display heteroskedasticity.
(Essay)
4.9/5 (26)
Using the textbook example of 420 California school districts and the regression of testscores on the student-teacher ratio, you find that the standard error on the slope coefficient is 0.51 when using the heteroskedasticity robust formula, while it is 0.48 when employing the homoskedasticity only formula. When calculating the t-statistic, the recommended procedure is to
(Multiple Choice)
4.8/5 (22)
Under the least squares assumptions (zero conditional mean for the error term, Xi and Yi being i.i.d., and Xi and ui having finite fourth moments), the OLS estimator for the slope and intercept
(Multiple Choice)
4.7/5 (36)
In the presence of heteroskedasticity, and assuming that the usual least squares assumptions hold, the OLS estimator is
(Multiple Choice)
4.8/5 (34)
(Requires Appendix material from Chapters 4 and 5)Shortly before you are making a group presentation on the testscore/student-teacher ratio results, you realize that one of your peers forgot to type all the relevant information on one of your slides. Here is what you see: = 698.9 - STR, R2 = 0.051, SER = 18.6
(9.47)(0.48)
In addition, your group member explains that he ran the regression in a standard spreadsheet program, and that, as a result, the standard errors in parenthesis are homoskedasticity-only standard errors.
(a)Find the value for the slope coefficient.
(b)Calculate the t-statistic for the slope and the intercept. Test the hypothesis that the intercept and the slope are different from zero.
(c)Should you be concerned that your group member only gave you the result for the homoskedasticity-only standard error formula, instead of using the heteroskedasticity-robust standard errors?
(Essay)
4.9/5 (34)
Your textbook discussed the regression model when X is a binary variable
Yi = ?0 + ?1Di + ui, i = 1..., n
Let Y represent wages, and let D be one for females, and 0 for males. Using the OLS formula for the slope coefficient, prove that is the difference between the average wage for males and the average wage for females.
(Essay)
4.8/5 (41)
The proof that OLS is BLUE requires all of the following assumptions with the exception of:
(Multiple Choice)
4.8/5 (25)
Explain carefully the relationship between a confidence interval, a one-sided hypothesis test, and a two-sided hypothesis test. What is the unit of measurement of the t-statistic?
(Essay)
4.7/5 (43)
The neoclassical growth model predicts that for identical savings rates and population growth rates, countries should converge to the per capita income level. This is referred to as the convergence hypothesis. One way to test for the presence of convergence is to compare the growth rates over time to the initial starting level, i.e., to run the regression = + × RelProd60 , where g6090 is the average annual growth rate of GDP per worker for the 1960-1990 sample period, and RelProd60 is GDP per worker relative to the United States in 1960. Under the null hypothesis of no convergence, ?1 = 0; H1 : ?1 < 0, implying ("beta")convergence. Using a standard regression package, you get the following output:
Dependent Variable: G6090
Method: Least Squares
Date: 07/11/06 Time: 05:46
Sample: 1 104
Included observations: 104
White Heteroskedasticity-Consistent Standard Errors & Covariance Variable Coefficient Std. Error t-Statistic Prob. C 0.018989 0.002392 7.939864 0.0000 YL60 -0.000566 0.005056 -0.111948 0.9111 R-squared 0.000068 Mean dependent var 0.018846 Adjusted R-squared -0.009735 S.D. dependent var 0.015915 S.E. of regression 0.015992 Akaike info criterion -5.414418 Sum squared resid 0.026086 Schwarz criterion -5.363565 Log likelihood 283.5498 F-statistic 0.006986 Durbin-Watson stat 1.367534 Prob(F-statistic) 0.933550
You are delighted to see that this program has already calculated p-values for you. However, a peer of yours points out that the correct p-value should be 0.4562. Who is right?
(Essay)
4.9/5 (35)
Your textbook discussed the regression model when X is a binary variable
Yi = ?0 + ?iDi + ui, i = 1,..., n
Let Y represent wages, and let D be one for females, and 0 for males. Using the OLS formula for the intercept coefficient, prove that is the average wage for males.
(Essay)
4.7/5 (26)
Changing the units of measurement obviously will have an effect on the slope of your regression function. For example, let Y*= aY and X* = bX. Then it is easy but tedious to show that Given this result, how do you think the standard errors and the regression R2 will change?
(Essay)
4.9/5 (26)
In order to formulate whether or not the alternative hypothesis is one-sided or two-sided, you need some guidance from economic theory. Choose at least three examples from economics or other fields where you have a clear idea what the null hypothesis and the alternative hypothesis for the slope coefficient should be. Write a brief justification for your answer.
(Essay)
4.8/5 (30)
The construction of the t-statistic for a one- and a two-sided hypothesis
(Multiple Choice)
4.8/5 (34)
The confidence interval for the sample regression function slope
(Multiple Choice)
4.9/5 (31)
(Requires Appendix material)Your textbook shows that OLS is a linear estimator 1 = , where For OLS to be conditionally unbiased, the following two conditions must hold: and = 1. Show that this is the case.
(Essay)
4.9/5 (36)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)