Exam 5: Regression With a Single Regressor: Hypothesis Tests and Confidence Intervals
Exam 1: Economic Questions and Data17 Questions
Exam 2: Review of Probability70 Questions
Exam 3: Review of Statistics65 Questions
Exam 4: Linear Regression With One Regressor65 Questions
Exam 5: Regression With a Single Regressor: Hypothesis Tests and Confidence Intervals59 Questions
Exam 6: Linear Regression With Multiple Regressors65 Questions
Exam 7: Hypothesis Tests and Confidence Intervals in Multiple Regression64 Questions
Exam 8: Nonlinear Regression Functions63 Questions
Exam 9: Assessing Studies Based on Multiple Regression65 Questions
Exam 10: Regression With Panel Data50 Questions
Exam 11: Regression With a Binary Dependent Variable50 Questions
Exam 12: Instrumental Variables Regression50 Questions
Exam 13: Experiments and Quasi-Experiments50 Questions
Exam 14: Introduction to Time Series Regression and Forecasting50 Questions
Exam 15: Estimation of Dynamic Causal Effects50 Questions
Exam 16: Additional Topics in Time Series Regression50 Questions
Exam 17: The Theory of Linear Regression With One Regressor49 Questions
Exam 18: The Theory of Multiple Regression50 Questions
Select questions type
The homoskedasticity-only estimator of the variance of 1 is
(Multiple Choice)
4.8/5  (42)
(42)
Using the California School data set from your textbook, you run the following regression: = 698.9 - 2.28 STR
n = 420, SER = 9.4
where TestScore is the average test score in the district and STR is the student-teacher ratio. The sample standard deviation of test scores is 19.05, and the sample standard deviation of the student teacher ratio is 1.89.
a.
Find the regression R2 and the correlation coefficient between test scores and the student teacher ratio.
b.
Find the homoskedasticity-only standard error of the slope.
(Essay)
4.9/5 (34)
(Continuation from Chapter 4, number 6)The neoclassical growth model predicts that for identical savings rates and population growth rates, countries should converge to the per capita income level. This is referred to as the convergence hypothesis. One way to test for the presence of convergence is to compare the growth rates over time to the initial starting level.
(a)The results of the regression for 104 countries were as follows: = 0.019 - 0.0006 × RelProd60, R2= 0.00007, SER = 0.016
(0.004)(0.0073)  where g6090 is the average annual growth rate of GDP per worker for the 1960-1990 sample period, and RelProd60 is GDP per worker relative to the United States in 1960. Numbers in parenthesis are heteroskedasticity robust standard errors.
Using the OLS estimator with homoskedasticity-only standard errors, the results changed as follows: = 0.019 - 0.0006×RelProd60, R2= 0.00007, SER = 0.016
(0.002)(0.0068)
Why didn't the estimated coefficients change? Given that the standard error of the slope is now smaller, can you reject the null hypothesis of no beta convergence? Are the results in the second equation more reliable than the results in the first equation? Explain.
(b)You decide to restrict yourself to the 24 OECD countries in the sample. This changes your regression output as follows (numbers in parenthesis are heteroskedasticity robust standard errors): = 0.048 - 0.0404 RelProd60, R2 = 0.82, SER = 0.0046
(0.004)(0.0063)
Test for evidence of convergence now. If your conclusion is different than in (a), speculate why this is the case.
(c)The authors of your textbook have informed you that unless you have more than 100 observations, it may not be plausible to assume that the distribution of your OLS estimators is normal. What are the implications here for testing the significance of your theory?
where g6090 is the average annual growth rate of GDP per worker for the 1960-1990 sample period, and RelProd60 is GDP per worker relative to the United States in 1960. Numbers in parenthesis are heteroskedasticity robust standard errors.
Using the OLS estimator with homoskedasticity-only standard errors, the results changed as follows: = 0.019 - 0.0006×RelProd60, R2= 0.00007, SER = 0.016
(0.002)(0.0068)
Why didn't the estimated coefficients change? Given that the standard error of the slope is now smaller, can you reject the null hypothesis of no beta convergence? Are the results in the second equation more reliable than the results in the first equation? Explain.
(b)You decide to restrict yourself to the 24 OECD countries in the sample. This changes your regression output as follows (numbers in parenthesis are heteroskedasticity robust standard errors): = 0.048 - 0.0404 RelProd60, R2 = 0.82, SER = 0.0046
(0.004)(0.0063)
Test for evidence of convergence now. If your conclusion is different than in (a), speculate why this is the case.
(c)The authors of your textbook have informed you that unless you have more than 100 observations, it may not be plausible to assume that the distribution of your OLS estimators is normal. What are the implications here for testing the significance of your theory?
(Essay)
4.9/5 (35)
Using 143 observations, assume that you had estimated a simple regression function and that your estimate for the slope was 0.04, with a standard error of 0.01. You want to test whether or not the estimate is statistically significant. Which of the following possible decisions is the only correct one:
(Multiple Choice)
4.8/5 (31)
Let be distributed N(0, ), i.e., the errors are distributed normally with a constant variance (homoskedasticity). This results in being distributed N(?1, ), where Statistical inference would be straightforward if was known. One way to deal with this problem is to replace with an estimator Clearly since this introduces more uncertainty, you cannot expect to be still normally distributed. Indeed, the t-statistic now follows Student's t distribution. Look at the table for the Student t-distribution and focus on the 5% two-sided significance level. List the critical values for 10 degrees of freedom, 30 degrees of freedom, 60 degrees of freedom, and finally ? degrees of freedom. Describe how the notion of uncertainty about can be incorporated about the tails of the t-distribution as the degrees of freedom increase.
(Essay)
4.8/5 (34)
You extract approximately 5,000 observations from the Current Population Survey (CPS)and estimate the following regression function: = 3.32 - 0.45 Age, R2= 0.02, SER = 8.66 (1.00)(0.04)
Where ahe is average hourly earnings, and Age is the individual's age. Given the specification, your 95% confidence interval for the effect of changing age by 5 years is approximately
(Multiple Choice)
4.8/5 (37)
Using the California School data set from your textbook, you run the following regression: = 698.9 - 2.28 STR
n = 420, R2 = 0.051, SER = 18.6
where TestScore is the average test score in the district and STR is the student-teacher ratio. Using heteroskedasticity robust standard errors, you find while choosing the homoskedasticity-only option, the standard error is 0.48.
a. Calculate the t-statistic for both standard errors.
b. Which of the two t-statistics should you base your inference on?
(Essay)
4.9/5 (34)
One of the following steps is not required as a step to test for the null hypothesis:
(Multiple Choice)
4.7/5 (23)
(Continuation of the Purchasing Power Parity question from Chapter 4)The news-magazine The Economist regularly publishes data on the so called Big Mac index and exchange rates between countries. The data for 30 countries from the April 29, 2000 issue is listed below:
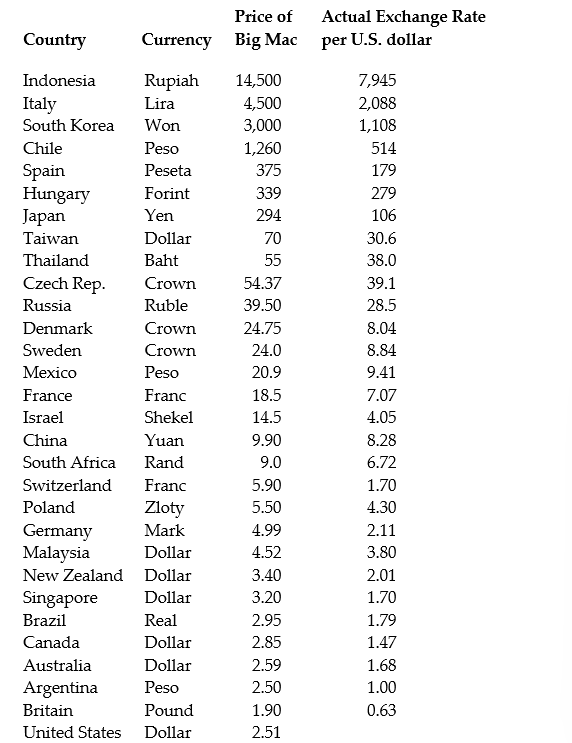 The concept of purchasing power parity or PPP ("the idea that similar foreign and domestic goods … should have the same price in terms of the same currency," Abel, A. and B. Bernanke, Macroeconomics, 4th edition, Boston: Addison Wesley, 476)suggests that the ratio of the Big Mac priced in the local currency to the U.S. dollar price should equal the exchange rate between the two countries.
After entering the data into your spread sheet program, you calculate the predicted exchange rate per U.S. dollar by dividing the price of a Big Mac in local currency by the U.S. price of a Big Mac ($2.51). To test for PPP, you regress the actual exchange rate on the predicted exchange rate.
The estimated regression is as follows: = -27.05 + 1.35 × 1.35×Pr edExRate R2 = 0.994, n = 29, SER = 122.15
(23.74)(0.02)
(a)Your spreadsheet program does not allow you to calculate heteroskedasticity robust standard errors. Instead, the numbers in parenthesis are homoskedasticity only standard errors. State the two null hypothesis under which PPP holds. Should you use a one-tailed or two-tailed alternative hypothesis?
(b)Calculate the two t-statistics.
(c)Using a 5% significance level, what is your decision regarding the null hypothesis given the two t-statistics? What critical values did you use? Are you concerned with the fact that you are testing the two hypothesis sequentially when they are supposed to hold simultaneously?
(d)What assumptions had to be made for you to use Student's t-distribution?
The concept of purchasing power parity or PPP ("the idea that similar foreign and domestic goods … should have the same price in terms of the same currency," Abel, A. and B. Bernanke, Macroeconomics, 4th edition, Boston: Addison Wesley, 476)suggests that the ratio of the Big Mac priced in the local currency to the U.S. dollar price should equal the exchange rate between the two countries.
After entering the data into your spread sheet program, you calculate the predicted exchange rate per U.S. dollar by dividing the price of a Big Mac in local currency by the U.S. price of a Big Mac ($2.51). To test for PPP, you regress the actual exchange rate on the predicted exchange rate.
The estimated regression is as follows: = -27.05 + 1.35 × 1.35×Pr edExRate R2 = 0.994, n = 29, SER = 122.15
(23.74)(0.02)
(a)Your spreadsheet program does not allow you to calculate heteroskedasticity robust standard errors. Instead, the numbers in parenthesis are homoskedasticity only standard errors. State the two null hypothesis under which PPP holds. Should you use a one-tailed or two-tailed alternative hypothesis?
(b)Calculate the two t-statistics.
(c)Using a 5% significance level, what is your decision regarding the null hypothesis given the two t-statistics? What critical values did you use? Are you concerned with the fact that you are testing the two hypothesis sequentially when they are supposed to hold simultaneously?
(d)What assumptions had to be made for you to use Student's t-distribution?
(Essay)
4.7/5 (38)
Imagine that you were told that the t-statistic for the slope coefficient of the regression line = 698.9 - 2.28 × STR was 4.38. What are the units of measurement for the t-statistic?
(Multiple Choice)
4.8/5 (43)
When estimating a demand function for a good where quantity demanded is a linear function of the price, you should
(Multiple Choice)
4.8/5 (33)
You have collected data for the 50 U.S. states and estimated the following relationship between the change in the unemployment rate from the previous year ( )and the growth rate of the respective state real GDP (gy). The results are as follows = 2.81 - 0.23 gy, R2= 0.36, SER = 0.78 (0.12)(0.04)
Assuming that the estimator has a normal distribution, the 95% confidence interval for the slope is approximately the interval
(Multiple Choice)
4.8/5 (33)
Assume that your population regression function is
Yi = ?iXi + ui
i.e., a regression through the origin (no intercept). Under the homoskedastic normal regression assumptions, the t-statistic will have a Student t distribution with n-1 degrees of freedom, not n-2 degrees of freedom, as was the case in Chapter 5 of your textbook. Explain. Do you think that the residuals will still sum to zero for this case?
(Essay)
4.8/5 (28)
The effect of decreasing the student-teacher ratio by one is estimated to result in an improvement of the districtwide score by 2.28 with a standard error of 0.52. Construct a 90% and 99% confidence interval for the size of the slope coefficient and the corresponding predicted effect of changing the student-teacher ratio by one. What is the intuition on why the 99% confidence interval is wider than the 90% confidence interval?
(Essay)
4.8/5 (44)
Below you are asked to decide on whether or not to use a one-sided alternative or a two-sided alternative hypothesis for the slope coefficient. Briefly justify your decision.
(a) = 0 + 1pi, where qd is the quantity demanded for a good, and p is its price.
(b) = 0 + 1
, where is the actual house price, and is the assessed house price. You want to test whether or not the assessment is correct, on average.
(c) i = 0 + 1
, where C is household consumption, and Yd is personal disposable income.
(Essay)
4.8/5 (30)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)