Exam 9: Assessing Studies Based on Multiple Regression
Assume the following model of the labor market:
Nd = ?0 + ?1
+ u
Ns = ?0 + ?1
+ v
Nd = Ns = N
where N is employment, (W/P)is the real wage in the labor market, and u and v are determinants other than the real wage which affect labor demand and labor supply (respectively). Let
E(u)= E(v)= 0; var(u)= ; var(v)= ; cov(u,v)= 0
Assume that you had collected data on employment and the real wage from a random sample of observations and estimated a regression of employment on the real wage (employment being the regressand and the real wage being the regressor). It is easy but tedious to show that > 0
since the slope of the labor supply function is positive and the slope of the labor demand function is negative. Hence, in general, you will not find the correct answer even in large samples.
a. What is this bias referred to?
b. What would the relationship between the variance of the labor supply/demand shift variable have to be for the bias to disappear?
c. Give an intuitive answer why the bias would disappear in that situation. Draw a graph to illustrate your argument.
a. Simultaneous equations bias
b. The variance of v, the shift variable of the labor supply curve, would have to be substantially larger compared to the variance of the labor demand shift variable.
c. Take the extreme case where the labor demand curve hardly shifts at all, but there are large changes in the labor supply curve caused by the shift variable v. In that case, the labor supply curve would "trace out "the labor demand curve. Since in real life you only observe the intersection of the demand and supply relationship, it becomes clear now why the simultaneous equation bias has been removed. 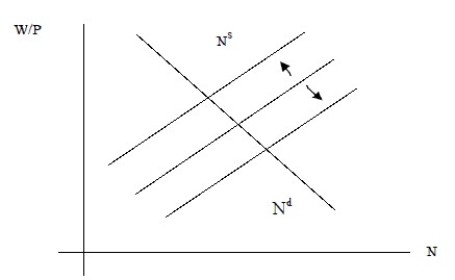
The reliability of a study using multiple regression analysis depends on all of the following with the exception of
C
Your textbook only analyzed the case of an error-in-variables bias of the type i= Xi + wi. What if the error were generated in the simple regression model by entering data that always contained the same typographical error, say i= Xi + a or i= bXi, where a and b are constants. What effect would this have on your regression model?
This would have an effect similar to changing the units of measurement. The measurement error is not random here, and the bias can be determined exactly.
For the case i= Xi + a, the slope will be unaffected and the usual properties for the OLS slope estimator will hold. However, since = + a and 0 = - 1
)- 1a, the intercept will be underestimated by the constant measurement error times the slope.
For the case i = bXi, the intercept is unaffected, but the ratio of the estimated slope with measurement error to the slope without measurement error is b.
Comparing the California test scores to test scores in Massachusetts is appropriate for external validity if
In the simple, one-explanatory variable, errors-in-variables model, the OLS estimator for the slope is inconsistent. The textbook derived the following result Show that the OLS estimator for the intercept behaves as follows in large samples: where
Possible solutions to omitted variable bias, when the omitted variable is not observed, include the following with the exception of
The true causal effect might not be the same in the population studied and the population of interest because
Your textbook gives the following example of simultaneous causality bias of a two equation system:
Yi = β0 + β1Xi + ui
Xi = + Yi + vi
In microeconomics, you studied the demand and supply of goods in a single market. Let the demand ( )and supply ( )for the i-th good be determined as follows, = β0 - β1Pi + ui, = - Pi + vi,
where P is the price of the good. In addition, you typically assume that the market clears.
Explain how the simultaneous causality bias applies in this situation. The textbook explained a positive correlation between Xi and ui for > 0 through an argument that started from "imagine that ui is negative." Repeat this exercise here.
The Phillips curve is a relationship in macroeconomics between the inflation rate (inf)and the unemployment rate (ur). Estimating the Phillips curve using quarterly data for the United States from 1962:I to 1995:IV, you find = 4.08 + 0.118 urt, R2 = 0.003, SER = 3.148
(1.11)(0.176)
(a)Explain why, at first glance, this is a surprising result.
(b)Do you think that there is omitted variable bias in the regression?
(c)What other threats to internal validity may be present?
(d)If you could find a proper specification for the Phillips curve using United States data, what external validity criteria would you suggest?
Your textbook compares the results of a regression of test scores on the student-teacher ratio using a sample of school districts from California and from Massachusetts. Before standardizing the test scores for California, you get the following regression result:
= 698.9 - 2.28×STR
n = 420, R2 = 0.051, SER = 18.6
In addition, you are given the following information: the sample mean of the student-teacher ratio is 19.64 with a standard deviation of 1.89, and the standard deviation of the test scores is 19.05.
a. After standardizing the test scores variable and running the regression again, what is the value of the slope? What is the meaning of this new slope here (interpret the result)?
b. What will be the new intercept? Now that test scores have been standardized, should you interpret the intercept?
c. Does the regression R2 change between the two regressions? What about the t-statistic for the slope estimator?
Your textbook used the California Standardized Testing and Reporting (STAR)data set on test student performance in Chapters 4-7. One justification for putting second to twelfth graders through such an exercise once a year is to make schools more accountable. The hope is that schools with low scores will improve the following year and in the future. To test for the presence of such an effect, you collect data from 1,000 L.A. County schools for grade 4 scores in 1998 and 1999, both for reading (Read)and mathematics (Maths). Both are on a scale from zero to one hundred. The regression results are as follows (homoskedasticity-only standard errors in parentheses): = 6.967+0.9192=0.825, SER =7.818 (0.542)(0.013) = 4.131+0.943, Re a==0.887, SER =6.416 (0.409)(0.011)
(a)Interpret the results and indicate whether or not the coefficients are significantly different from zero. Do the coefficients have the expected sign and magnitude?
(b)Discuss various threats to internal and external validity, and try to assess whether or not these are likely to be present in your study.
(c)Changing the estimation method to allow for heteroskedasticity-robust standard errors produces four new standard errors: (0.539), (0.015), (0.452), and (0.015)in the order of appearance in the two equations above. Given these numbers, do any of your statements in (b)change? Do you think that the coefficients themselves changed?
(d)If reading and maths scores were the same in 1999 as in 1998, on average, what coefficients would you expect for the intercept and the slope? How would you test for the restrictions?
(e)The appropriate F-statistic in (d)is 138.27 for the maths scores, and 104.85 for the reading scores. Comparing these values to the critical values in the F table, can you reject the null hypothesis in each case?
(f)Your professor tells you that the analysis reminds her of "Galton's Fallacy." Sir Francis Galton regressed the height of children on the average height of their parents. He found a positive intercept and a slope between zero and one. Being concerned about the height of the English aristocracy, he interpreted the results as "regression to mediocrity" (hence the name regression). Do you see the parallel?
Applying the analysis from the California test scores to another U.S. state is an example of looking for
You have decided to analyze the year-to-year variation in temperature data. Specifically you want to use this year's temperature to predict next year's temperature for certain cities. As a result, you collect the daily high temperature (Temp)for 100 randomly selected days in a given year for three United States cities: Boston, Chicago, and Los Angeles. You then repeat the exercise for the following year. The regression results are as follows (heteroskedasticity-robust standard errors in parentheses): , SER
(6.46)
Temp
(3.98) (0.05)
(15.33) (0.22)
(a)What is the prediction of the above regression for Los Angeles if the temperature in the previous year was 75 degrees? What would be the prediction for Boston?
(b)Assume that the previous year's temperature gives accurate predictions, on average, for this year's temperature. What values would you expect in this case for the intercept and slope? Sketch how each of the above regressions behaves compared to this line.
(c)After reflecting on the results a bit, you consider the following explanation for the above results. Daily high temperatures on any given date are measured with error in the following sense: for any given day in any of the three cities, say January 28, there is a true underlying seasonal temperature (X), but each year there are different temporary weather patterns (v, w)which result in a temperature different from X. For the two years in your data set, the situation can be described as follows: = X + vt and = X + wt
Subtracting from , you get = + wt - vt. Hence the population parameter for the intercept and slope are zero and one, as expected. Show that the OLS estimator for the slope is inconsistent, where (d)Use the formula above to explain the differences in the results for the three cities. Is your mathematical explanation intuitively plausible?
Assume that you had found correlation of the residuals across observations. This may happen because the regressor is ordered by size. Your regression model could therefore be specified as follows:
Yi = β0 + β1Xi + ui
ui = ρui-1 + vi; < 1.
Furthermore, assume that you had obtained consistent estimates for β0, β1, ρ. If asked to make a prediction for Y, given a value of X(= Xj)and j-1, how would you proceed? Would you use the information on the lagged residual at all? Why or why not?
You have read the analysis in chapter 9 and want to explore the relationship between poverty and test scores. You decide to start your analysis by running a regression of test scores on the percent of students who are eligible to receive a free/reduced price lunch both in California and in Massachusetts. The results are as follows: CA = 681.44 - 0.610×PctLchCA
(0.99)(0.018)
n = 420, R2 = 0.75, SER = 9.45 MA = 731.89 - 0.788×PctLchMA
(0.95)(0.045)
n = 220, R2 = 0.61, SER = 9.41
Numbers in parenthesis are heteroskedasticity-robust standard errors.
a. Calculate a t-statistic to test whether or not the two slope coefficients are the same.
b. Your textbook compares the slope coefficients for the student-teacher ratio instead of the percent eligible for a free lunch. The authors remark: "Because the two standardized tests are different, the coefficients themselves cannot be compared directly: One point on the Massachusetts test is not the same as one point on the California test." What solution do they suggest?
Your textbook has analyzed simultaneous equation systems in the case of two equations,
Yi = β0 + β1Xi + ui
Xi = + Yi + vi,
where the first equation might be the labor demand equation (with capital stock and technology being held constant), and the second the labor supply equation (X being the real wage, and the labor market clears). What if you had a a production function as the third equation
Zi = + Yi + wi
where Z is output. If the error terms, u, v, and w, were pairwise uncorrelated, explain why there would be no simultaneous causality bias when estimating the production function using OLS.
Misspecification of functional form of the regression function
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)