Exam 20: Model Building
Exam 1: What Is Statistics14 Questions
Exam 2: Types of Data, Data Collection and Sampling16 Questions
Exam 3: Graphical Descriptive Methods Nominal Data19 Questions
Exam 4: Graphical Descriptive Techniques Numerical Data64 Questions
Exam 5: Numerical Descriptive Measures147 Questions
Exam 6: Probability106 Questions
Exam 7: Random Variables and Discrete Probability Distributions55 Questions
Exam 8: Continuous Probability Distributions117 Questions
Exam 9: Statistical Inference: Introduction8 Questions
Exam 10: Sampling Distributions65 Questions
Exam 11: Estimation: Describing a Single Population127 Questions
Exam 12: Estimation: Comparing Two Populations22 Questions
Exam 13: Hypothesis Testing: Describing a Single Population129 Questions
Exam 14: Hypothesis Testing: Comparing Two Populations78 Questions
Exam 15: Inference About Population Variances49 Questions
Exam 16: Analysis of Variance115 Questions
Exam 17: Additional Tests for Nominal Data: Chi-Squared Tests110 Questions
Exam 18: Simple Linear Regression and Correlation213 Questions
Exam 19: Multiple Regression121 Questions
Exam 20: Model Building92 Questions
Exam 21: Nonparametric Techniques126 Questions
Exam 22: Statistical Inference: Conclusion103 Questions
Exam 23: Time-Series Analysis and Forecasting145 Questions
Exam 24: Index Numbers25 Questions
Exam 25: Decision Analysis51 Questions
Select questions type
A professor of accounting wanted to develop a multiple regression model to predict the students' grades in her fourth-year accounting course. She decides that the two most important factors are the student's grade point average (GPA) in the first three years and the student's major. She proposes the model: .
where
y
= fourth-year accounting course mark (out of 100). = GPA in first three years (range 0 to 12). = 1 if student's major is accounting.
= 0 if not. = 1 if student's major is finance.
= 0 if not.
The computer output is shown below.
THE REGRESSION EQUATION IS . Predictor Coef SDev T Constant 9.14 7.10 1.287 6.73 1.91 3.524 10.42 4.16 2.505 5.16 3.93 1.313 S = 15.0 R-Sq = 44.2%. ANALYSIS OF VARIANCE Source of Variation df SS MS F Regression 3 17098 5699.333 25.386 Error 96 21553 224.510 Total 99 38651 Do these results allow us to conclude at the 1% significance level that the model is useful in predicting the fourth-year accounting course mark?
Free
(Essay)
5.0/5  (22)
(22)
Correct Answer: Verified
Verified
. At least one is not equal to zero.
Rejection region: F > 3.95.
Test statistic: F = 25.386.
Conclusion: Reject the null hypothesis. Yes.
In the first-order regression model ŷ = 12 + 6x1 +8x2 + 4x1x2, a unit increase in x1 increases the value of on average by 6 units.
Free
(True/False)
4.9/5 (33)
Correct Answer:Verified
False
In the first-order model 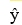 = 60 + 40x1 -10x2 + 5x1x2, a unit increase in x1, while holding x2 constant at 1, increases the value of on average by 45 units.
= 60 + 40x1 -10x2 + 5x1x2, a unit increase in x1, while holding x2 constant at 1, increases the value of on average by 45 units.
Free
(True/False)
4.8/5 (35)
Correct Answer:Verified
True
We interpret the coefficients in a multiple regression model by holding all variables in the model constant.
(True/False)
4.8/5 (37)
Stepwise regression is especially useful when there are many independent variables.
(True/False)
4.8/5 (32)
The graph of the model 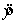 is shaped like a straight line going upwards.
is shaped like a straight line going upwards.
(True/False)
4.9/5 (38)
An economist is analysing the incomes of professionals (physicians, dentists and lawyers). He realises that an important factor is the number of years of experience. However, he wants to know if there are differences among the three professional groups. He takes a random sample of 125 professionals and estimates the multiple regression model: .
where
y
= annual income (in $1000). = years of experience. = 1 if physician.
= 0 if not. = 1 if dentist.
= 0 if not.
The computer output is shown below.
THE REGRESSION EQUATION IS . Predictor Coef SDev T Constant 71.65 18.56 3.860 2.07 0.81 2.556 10.16 3.16 3.215 -7.44 2.85 -2.611 S = 42.6 R-Sq = 30.9%. ANALYSIS OF VARIANCE Source of Variation df SS MS F Regression 3 98008 32669.333 18.008 Error 121 219508 1814.116 Total 124 317516 Do these results allow us to conclude at the 1% significance level that the model is useful in predicting the income of professionals?
(Essay)
4.8/5 (42)
A traffic consultant has analysed the factors that affect the number of traffic fatalities. She has come to the conclusion that two important variables are the number of cars and the number of tractor-trailer trucks. She proposed the second-order model with interaction: .
Where:
y = number of annual fatalities per shire. = number of cars registered in the shire (in units of 10 000). = number of trucks registered in the shire (in units of 1000).
The computer output (based on a random sample of 35 shires) is shown below.
THE REGRESSION EQUATION IS . Predictor Coef SDev T Constant 69.7 41.3 1.688 11.3 5.1 2.216 7.61 2.55 2.984 -1.15 0.64 -1.797 -0.51 0.20 -2.55 -0.13 0.10 -1.30 S = 15.2 R-Sq = 47.2%.
ANALYSIS OF VARIANCE Source of df SS MS F Variation Regression 5 5959 1191.800 5.181 Error 29 6671 230.034 Total 34 12630 Test at the 1% significance level to determine whether the term should be retained in the model.
(Essay)
4.7/5 (36)
Which of the following is another name for a dummy variable?
(Multiple Choice)
5.0/5 (36)
The model is used whenever the statistician believes that, on average, is linearly related to and , and the predictor variables do not interact.
(True/False)
4.7/5 (30)
A first-order model was used in a regression analysis involving 25 observations to study the relationship between a dependent variable y and three independent variables, , and . The analysis showed that the mean squares for regression is 160 and the sum of squares for error is 1050. In addition, the following is a partial computer printout. Predictor Coef StDev Constant 25 4 18 6 -12 4.8 6 5 Is there enough evidence at the 5% significance level to conclude that the model is useful in predicting the value of y?
(Essay)
4.8/5 (43)
A traffic consultant has analysed the factors that affect the number of traffic fatalities. She has come to the conclusion that two important variables are the number of cars and the number of tractor-trailer trucks. She proposed the second-order model with interaction: .
Where:
y = number of annual fatalities per shire. = number of cars registered in the shire (in units of 10 000). = number of trucks registered in the shire (in units of 1000).
The computer output (based on a random sample of 35 shires) is shown below.
THE REGRESSION EQUATION IS . Predictor Coef SDev T Constant 69.7 41.3 1.688 11.3 5.1 2.216 7.61 2.55 2.984 -1.15 0.64 -1.797 -0.51 0.20 -2.55 -0.13 0.10 -1.30 S = 15.2 R-Sq = 47.2%.
ANALYSIS OF VARIANCE Source of df SS MS F Variation Regression 5 5959 1191.800 5.181 Error 29 6671 230.034 Total 34 12630 Is there enough evidence at the 5% significance level to conclude that the model is useful in predicting the number of fatalities?
(Essay)
4.7/5 (29)
Suppose that the sample regression line of a first-order model is . If we examine the relationship between y and for three different values of , we observe that the effect of on remains the same no matter what the value of .
(True/False)
4.8/5 (44)
An avid football fan was in the process of examining the factors that determine the success or failure of football teams. He noticed that teams with many rookies and teams with many veterans seem to do quite poorly. To further analyse his beliefs, he took a random sample of 20 teams and proposed a second-order model with one independent variable. The selected model is: .
where
y = winning team's percentage.
x = average years of professional experience.
The computer output is shown below:
THE REGRESSION EQUATION IS: Predictor Coef S2Dev T Constant 32.6 19.3 1.689 x 5.96 2.41 2.473 -0.48 0.22 -2.182 S = 16.1 R-Sq = 43.9%.
ANALYSIS OF VARIANCE Source of Variation df SS MS F Regression 2 3452 1726 6.663 Error 17 4404 259.059 Total 19 7856 Test to determine at the 10% significance level whether the term should be retained.
(Essay)
4.8/5 (32)
In general, to represent a nominal independent variable that has n possible categories, we would create n dummy variables.
(True/False)
4.9/5 (35)
In regression analysis, indicator variables may be used as independent variables.
(True/False)
4.9/5 (43)
Suppose that the sample regression equation of a model is
. If we examine the relationship between y and for = 1, 2 and 3, we observe that the three equations produced not only differ in the intercept term, but the coefficient of also varies.
(True/False)
4.8/5 (32)
In the first-order model
, a unit increase in , while holding constant at a value of 2, decreases the value of on average by 8 units.
(True/False)
4.8/5 (37)
Suppose that the estimated regression equation for 200 business graduates is ŷ = 20 000 + 2000x + 1500I,
Where y is the starting salary, x is the grade point average and I is an indicator variable that takes the value of 1 if the student is a computer information systems major and 0 if not. A business administration major graduate with a grade point average of 4 would have an average starting salary of:
(Multiple Choice)
4.7/5 (45)
An economist is in the process of developing a model to predict the price of gold. She believes that the two most important variables are the price of a barrel of oil and the interest rate She proposes the first-order model with interaction: .
A random sample of 20 daily observations was taken. The computer output is shown below.
THE REGRESSION EQUATION IS
Predictor Coef SDDev T Constant 115.6 78.1 1.480 22.3 7.1 3.141 14.7 6.3 2.333 -1.36 0.52 -2.615
ANALYSIS OF VARIANCE
Source of Variation df SS MS F Regression 3 8661 2887.0 6.626 Error 16 6971 435.7 Total 19 15632 Is there sufficient evidence at the 1% significance level to conclude that the price of a barrel of oil and the price of gold are linearly related?
(Essay)
4.8/5 (24)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)