Exam 5: Regression With a Single Regressor: Hypothesis Tests and Confidence Intervals
Exam 1: Economic Questions and Data11 Questions
Exam 2: Review of Probability61 Questions
Exam 3: Review of Statistics56 Questions
Exam 4: Linear Regression With One Regressor54 Questions
Exam 5: Regression With a Single Regressor: Hypothesis Tests and Confidence Intervals53 Questions
Exam 6: Linear Regression With Multiple Regressors54 Questions
Exam 7: Hypothesis Tests and Confidence Intervals in Multiple Regression50 Questions
Exam 8: Nonlinear Regression Functions53 Questions
Exam 9: Assessing Studies Based on Multiple Regression55 Questions
Exam 10: Regression With Panel Data40 Questions
Exam 11: Regression With a Binary Dependent Variable40 Questions
Exam 12: Instrumental Variables Regression40 Questions
Exam 13: Experiments and Quasi-Experiments40 Questions
Exam 14: Introduction to Time Series Regression and Forecasting36 Questions
Exam 15: Estimation of Dynamic Causal Effects40 Questions
Exam 16: Additional Topics in Time Series Regression40 Questions
Exam 17: The Theory of Linear Regression With One Regressor39 Questions
Exam 18: The Theory of Multiple Regression38 Questions
Select questions type
You have obtained measurements of height in inches of 29 female and 81 male
students (Studenth)at your university.A regression of the height on a constant
and a binary variable (BFemme), which takes a value of one for females and is
zero otherwise, yields the following result: = 71.0-4.84\times BFemme ,=0.40,SER=2.0 (0.3)(0.57) (a)What is the interpretation of the intercept? What is the interpretation of the slope?
How tall are females, on average?
(Essay)
5.0/5  (37)
(37)
Consider the sample regression function
The table below lists estimates for the slope and the variance of the slope estimator In each case calculate the p -value for the null hypothesis of and a two-tailed alternative hypothesis. Indicate in which case you would reject the null hypothesis at the 5 % significance level.
-1.76 0.0025 2.85 -0.00014 0.37 0.000003 117.5 0.0000013
(Essay)
4.9/5 (33)
Imagine that you were told that the t -statistic for the slope coefficient of the regression line was 4.38 . What are the units of measurement for the t -statistic?
(Multiple Choice)
4.9/5 (33)
Assume that your population regression function is i.e., a regression through the origin (no intercept).Under the homoskedastic
normal regression assumptions, the t-statistic will have a Student t distribution
with n-1 degrees of freedom, not n-2 degrees of freedom, as was the case in
Chapter 5 of your textbook.Explain.Do you think that the residuals will still sum
to zero for this case?
(Essay)
4.8/5 (39)
(continuation from Chapter 4) Sir Francis Galton, a cousin of James Darwin, examined the relationship between the height of children and their parents towards the end of the century. It is from this study that the name "regression" originated. You decide to update his findings by collecting data from 110 college students, and estimate the following relationship:
= 19.6+0.73\times Midparh, =0.45,SER=2.0 (7.2)(0.10) where Studenth is the height of students in inches, and Midparh is the average of
the parental heights.Values in parentheses are heteroskedasticity robust standard
errors.(Following Galton's methodology, both variables were adjusted so that the
average female height was equal to the average male height.)
(a)Test for the statistical significance of the slope coefficient.
(Essay)
4.7/5 (33)
(Requires Appedix material and Calculus) Equation (5.36) in your textbook derives the conditional variance for any old conditionally unbiased estimator to be (where the conditions for conditional unbiasedness are and . As an alternative to the BLUE proof presented in your textbook, you recall from one of your calculus courses that you could minimize the variance subject to the two constraints, thereby making the variance as small as possible while the constraints are holding. Show that in doing so you get the OLS weights . (You may assume that are nonrandom (fixed over repeated samples.)) 22
(Essay)
4.8/5 (40)
The neoclassical growth model predicts that for identical savings rates and population growth rates, countries should converge to the per capita income level. This is referred to as the convergence hypothesis. One way to test for the presence of convergence is to compare the growth rates over time to the initial starting level, i.e., to run the regression , where is the average annual growth rate of GDP per worker for the 1960-1990 sample period, and is GDP per worker relative to the United States in 1960. Under the null hypothesis of no convergence, , implying ("beta") convergence. Using a standard regression package, you get the following output: Dependent Variable: G6090
Method: Least Squares
Date: 07/11/06 Time: 05:46
Sample: 1104
Included observations: 104
White Heteroskedasticity-Consistent Standard Errors & Covariance
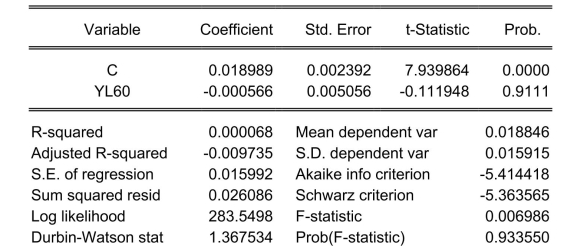 You are delighted to see that this program has already calculated p-values for you.
However, a peer of yours points out that the correct p-value should be 0.4562.
Who is right?
You are delighted to see that this program has already calculated p-values for you.
However, a peer of yours points out that the correct p-value should be 0.4562.
Who is right?
(Essay)
4.9/5 (40)
The only difference between a one- and two-sided hypothesis test is
(Multiple Choice)
4.8/5 (39)
Your textbook discussed the regression model when X is a binary variable Let represent wages, and let be one for females, and 0 for males. Using the OLS formula for the slope coefficient, prove that is the difference between the average wage for males and the average wage for females.
(Essay)
4.8/5 (34)
(continuation from Chapter 4, number 3)You have obtained a sub-sample of 1744
individuals from the Current Population Survey (CPS)and are interested in the
relationship between weekly earnings and age.The regression, using
heteroskedasticity-robust standard errors, yielded the following result: = 239.16+5.20\times Age ,=0.05, SER =287.21., (20.24)(0.57)
where Earn and Age are measured in dollars and years respectively.
(a)Is the relationship between Age and Earn statistically significant?
(Essay)
4.8/5 (35)
The proof that OLS is BLUE requires all of the following assumptions with the exception of: a. the errors are homoskedastic.
b. the errors are normally distributed.
c. .
d. large outliers are unlikely.
(Short Answer)
4.7/5 (43)
In general, the t-statistic has the following form: a. .
b. .
c. .
d.
(Short Answer)
4.8/5 (36)
Consider the following regression line:
You are told that the t -statistic on the slope coefficient is 4.38 . What is the standard error of the slope coefficient?
(Multiple Choice)
4.9/5 (36)
With heteroskedastic errors, the weighted least squares estimator is BLUE.You should use OLS with heteroskedasticity-robust standard errors because
(Multiple Choice)
4.8/5 (30)
Carefully discuss the advantages of using heteroskedasticity-robust standard
errors over standard errors calculated under the assumption of homoskedasticity.
Give at least five examples where it is very plausible to assume that the errors
display heteroskedasticity.
(Essay)
5.0/5 (41)
One of the following steps is not required as a step to test for the null hypothesis: a. compute the standard error of .
b. test for the errors to be normally distributed.
c. compute the -statistic.
d. compute the -value.
(Short Answer)
4.8/5 (33)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)