Exam 12: Multiple Regression and Model Building
Exam 1: Statistics, Data, and Statistical Thinking77 Questions
Exam 2: Methods for Describing Sets of Data187 Questions
Exam 3: Probability284 Questions
Exam 4: Discrete Random Variables134 Questions
Exam 5: Continuous Random Variables138 Questions
Exam 6: Sampling Distributions52 Questions
Exam 7: Inferences Based on a Single Sample: Estimation With Confidence Intervals125 Questions
Exam 8: Inferences Based on a Single144 Questions
Exam 9: Inferences Based on Two Samples: Confidence Intervals and Tests of Hypotheses100 Questions
Exam 10: Analysis of Variance: Comparing More Than Two Means91 Questions
Exam 11: Simple Linear Regression113 Questions
Exam 12: Multiple Regression and Model Building131 Questions
Exam 13: Categorical Data Analysis60 Questions
Exam 14: Nonparametric Statistics Available Online87 Questions
Select questions type
It is desired to build a regression model to predict the sales price of a single family home, based on the size of the house and the neighborhood the home is located in. The goal is to compare the prices of homes that are located in two different neighborhoods. The following complete 2nd-order model is proposed: .
What hypothesis should be tested to determine if the quadratic terms are necessary to predict the sales price of a home?
Free
(Multiple Choice)
4.7/5  (27)
(27)
Correct Answer: Verified
Verified
A
In the quadratic model , a negative value of indicates downward concavity.
Free
(True/False)
4.8/5 (35)
Correct Answer:Verified
False
During its manufacture, a product is subjected to four different tests in sequential order. An efficiency expert claims that the fourth (and last) test is unnecessary since its results can be predicted based on the first three tests. To test this claim, multiple regression will be used to model Test4 score , as a function of Test1 score , Test 2 score , and Test3 score ). [Note: All test scores range from 200 to 800 , with higher scores indicative of a higher quality product.] Consider the model:
The first-order model was fit to the data for each of 12 units sampled from the production line. The results are summarized in the printout. SOURCE DF SS MS FVALUE PROB >F MODEL 3 151417 50472 18.16 .0075 ERROR 8 22231 2779 TOTAL 12 173648
ROOT MSE 52.72 R-SQUARE 0.872 DEP MEAN 645.8 ADJ R-SQ 0.824
PARAMETER STANDARD T FOR 0: VARIABLE ESTIMATE ERROR PARAMETER =0 PROB >|| INTERCEPT 11.98 80.50 0.15 0.885 X1(TEST1) 0.2745 0.1111 2.47 0.039 X2(TEST2) 0.3762 0.0986 3.82 0.005 X3(TEST3) 0.3265 0.0808 4.04 0.004
Suppose the confidence interval for is . Which of the following statements is incorrect?
Free
(Multiple Choice)
4.7/5 (33)
Correct Answer:Verified
D
The complete second-order model was fit to data points. The printout is shown below.
ANOVA

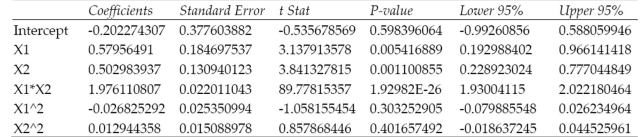 a. Write the complete second-order model for the data.
b. Is there sufficient evidence to indicate that at least one of the parameters , and is nonzero? Test using .
c. Test against . Use .
d. Test against . Use .
a. Write the complete second-order model for the data.
b. Is there sufficient evidence to indicate that at least one of the parameters , and is nonzero? Test using .
c. Test against . Use .
d. Test against . Use .
(Essay)
4.9/5 (31)
A certain type of rare gem serves as a status symbol for many of its owners. In theory, for
low prices, the demand decreases as the price of the gem increases. However, experts
hypothesize that when the gem is valued at very high prices, the demand increases with
price due to the status the owners believe they gain by obtaining the gem. Thus, the model
proposed to best explain the demand for the gem by its price is the quadratic model where y = Demand (in thousands)and x = Retail price per carat (dollars).
This model was fit to data collected for a sample of 12 rare gems. A portion of the printout
is given below: SOURCE DF SS MS F PR > Model 2 115145 57573 373 .0001 Error 9 1388 154 TOTAL 11 116533 Root MSE 12.42 R-Square .988
PARAMETER T for HO: VARIABLES ESTIMATES STD. ERROR PARAMETER =0 PR >|| INTERPCEP 286.42 9.66 29.64 .0001 X -.31 .06 -5.14 .0006 X.X .000067 .00007 .95 .3647
Does the quadratic term contribute useful information for predicting the demand for the gem? Use .
(Essay)
4.8/5 (39)
As part of a study at a large university, data were collected on n = 224 freshmen computer
science (CS)majors in a particular year. The researchers were interested in modeling y, a
studentʹs grade point average (GPA)after three semesters, as a function of the following
independent variables (recorded at the time the students enrolled in the university): average high school grade in mathematics (HSM)
average high school grade in science (HSS)
average high school grade in English (HSE)
SAT mathematics score (SATM)
SAT verbal score (SATV)
A first-order model was fit to data with .
Interpret the value of the adjusted coefficient of determination .
(Essay)
4.8/5 (33)
In any production process in which one or more workers are engaged in a variety of tasks, the total time spent in production varies as a function of the size of the workpool and the level of output of the various activities. In a large metropolitan department store, it is believed that the number of man-hours worked per day by the clerical staff depends on the number of pieces of mail processed per day and the number of checks cashed per day . Data collected for working days were used to fit the model:
A partial printout for the analysis follows:
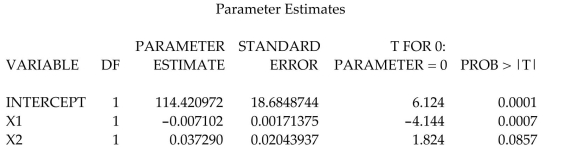 Calculate a confidence interval for .
Calculate a confidence interval for .
(Multiple Choice)
4.8/5 (37)
An elections officer wants to model voter turnout (y)in a precinct as a function of the type of precinct. Consider the model relating mean voter turnout, , to precinct type:
E(y)=++, where =1 if urban, 0 if not =1 if suburban, 0 if not (Base level = rural)
Interpret the value of .
(Multiple Choice)
4.8/5 (31)
For a multiple regression model, we assume that the mean of the probability distribution of the
random error is 0.
(True/False)
4.8/5 (37)
During its manufacture, a product is subjected to four different tests in sequential order. An efficiency expert claims that the fourth (and last) test is unnecessary since its results can be predicted based on the first three tests. To test this claim, multiple regression will be used to model Test4 score (y), as a function of Test1 score , Test 2 score , and Test3 score ( ). [Note: All test scores range from 200 to 800 , with higher scores indicative of a higher quality product.] Consider the model:
The first-order model was fit to the data for each of 12 units sampled from the production line. The results are summarized in the printout.
SOURCE DF SS MS F VALUE PROB > F MODEL 3 151417 50472 18.16 .0075 ERROR 8 22231 2779 TOTAL 12 173648
ROOT MSE 52.72 R-SQUARE 0.872 DEP MEAN 645.8 ADJ R-SQ 0.824
PARAMETER STANDARD T FOR 0: VARIABLE ESTIMATE ERROR PARAMETER =0 PROB >|| INTERCEPT 11.98 80.50 0.15 0.885 X1(TEST1) 0.2745 0.1111 2.47 0.039 X2(TEST2) 0.3762 0.0986 3.82 0.005 X3(TEST3) 0.3265 0.0808 4.04 0.004
Compute a confidence interval for .
(Multiple Choice)
4.7/5 (32)
In regression, it is desired to predict the dependent variable based on values of other related independent variables. Occasionally, there are relationships that exist between the independent
Variables. Which of the following multiple regression pitfalls does this example describe?
(Multiple Choice)
4.9/5 (39)
The printout shows the results of a first-order regression analysis relating the sales price of a product to the time in hours and the cost of raw materials needed to make the product.
SUMMARY OUTPUT
Regression Statistics Multiple R 0.997578302 R Square 0.995162468 Adjusted R Square 0.990324936 Standard Error 1.185250723 Observations 5
ANOVA
df SS MS F Significance F Regression 2 577.9903614 288.9952 205.717 0.004837532 Residual 2 2.809638554 1.404819 Total 4 580.8
Coefficients Standard Error t Stat P-value Lower 95\% Upper 95\% Intercept -26.48433735 3.674668773 -7.20727 0.018713 -42.29517198 -10.67350271 Time -2.168674699 4.11406532 -0.52714 0.650732 -19.8700814 15.532732 12.85220666 Materials 8.142168675 1.094681583 7.437933 0.0176 3.432130693 12.05
a. What is the least squares prediction equation?
b. Identify the SSE from the printout.
c. Find the estimator of for the model.
(Essay)
4.8/5 (41)
We decide to conduct a multiple regression analysis to predict the attendance at a major league baseball game. We use the size of the stadium as a quantitative independent variable and the type
Of game as a qualitative variable (with two levels - day game or night game). We hypothesize the
Following model:
Where size of the stadium
if a day game, 0 if a night game
A plot of the relationship would show:
(Multiple Choice)
4.9/5 (35)
Retail price data for n = 60 hard disk drives were recently reported in a computer magazine. Three variables were recorded for each hard disk drive: Retail PRICE (measured in dollars)
Microprocessor SPEED (measured in megahertz)
(Values in sample range from 10 to 40 )
CHIP size (measured in computer processing units)
(Values in sample range from 286 to 486 )
A first-order regression model was fit to the data. Part of the printout follows:
 Identify and interpret the estimate for the SPEED -coefficient, .
Identify and interpret the estimate for the SPEED -coefficient, .
(Multiple Choice)
4.8/5 (34)
A nested model F-test can only be used to determine whether second-order terms should be
included in the model.
(True/False)
4.9/5 (35)
Consider the model where is a quantitative variable and and are dummy variables describing a qualitative variable at three levels using the coding scheme
The resulting least squares prediction equation is . What is the response line (equation) for when and ?
(Multiple Choice)
4.7/5 (30)
We expect all or almost all of the residuals to fall within 2 standard deviations of 0.
(True/False)
4.8/5 (42)
In the first-order model represents the slope of the line relating to when and are both held fixed.
(True/False)
4.8/5 (38)
The confidence interval for the mean E(y)is narrower that the prediction interval for y.
(True/False)
5.0/5 (26)
One advantage to writing a single model that includes all levels of a qualitative variable rather a
separate model for each level is that we obtain a pooled estimate of
(True/False)
4.8/5 (33)
Filters
- Essay(0)
- Multiple Choice(0)
- Short Answer(0)
- True False(0)
- Matching(0)